How fast do I talk?
I speak very fast. It’s like the words are piled up in my mouth and I can’t say one without the rest tumbling out. Through my whole life people have told me to slow down, speak more clearly, and enunciate. I can do it if I concentrate but I quickly relapse into gushing out words.
As I now give lots of conference talks, this has become a professional issue:
- It’s harder to understand what I say
- The talks are much denser, as I cover more ground per minute
- I need to write a lot more material to cover the time slot, which is mentally exhausting
- I can’t guess how much time a draft takes without reciting it.
I want to slow down. But “slowing down” is hard. How slow is slow enough? How do I practice speaking slowly? How fast do I talk, anyway?
I could recite a fixed text and see how long it takes, but that’s too artificial for me. I want real data of how fast I slur my talks. I need to take existing talks and count my average words per minute. And I want to do this cheaply and quickly, without having to listen to the whole talk and painstakingly count the words. This means automatic transcription.
I’m also a big believer in showing the whole process. I took notes through the project so I could share how I did things and the issues I ran into.
The Goal
Here’s what I need:
- The total count of words I say in a conference talk. This would let me find my overall speaking pace.
- A way to remove sections that are not me talking. This would be things like speaker introductions, applause at the end, questions. Including them will give me poorer data.
- A way to measure my pace at finer resolution than “one talk”. Then I could measure standard deviation, or how much my speaking rate varies over the course of the talk.
- A way to plot my pace over the course of a talk. Then I can see if difference speaking paces correspond to different sections of the talk, or if I uniformly speed up the further into the talk I get.
The MVP is getting the total words per minute (wpm). That’s just words-in-talk / talk-time. As a first-order estimate, let’s look at Barack Obama’s Inaugural Address. That’s 120 words a minute. Assuming I want a 10% variance, I should be able to miss something like 12 words a minute and still be accurate enough. I don’t need good transcription, just any transcription. Even if it’s bad, if it gets most of the words right then I can get useful data. This means I can use something off-the-shelf and not worry about its accuracy.
So the short term goal: transcribe the audio from a video of my talk. I downloaded a copy of my distributed systems and TLA+ talk to try this with.
Transcription
I assumed that transcription software would just output the text without any timing info. If I wanted the get the timing, I’d have to manually match up the audio and transcription. Alternatively, I can break the audio into minute-long segments and transcribe them individually. Since finding the total wpm is my priority, let’s start with transcribing everything at once.
Local Transcription
I found this guide to transcribing audio. Here’s what I did:
- Install
ffmpeg,pydub, andSpeechRecognition. - Use
ffmpegto convert the mp4 to wav. - Load the wav until a python REPL with
pydub, for passing intoSpeechRecognition. - Discover that
SpeechRecognitiononly accepts paths to audio files, not the memory representations (or file objects). Usingpydubwas unnecessary. - Directly import the .wav into
SpeechRecognition. Run therecordfunction. - Get a timeout error from the Google API, which the package used by default. Read the docs, find that local transcription uses sphinx and I need to install both
SphinxbaseandPocketsphinx. - Neither
sphinxhas a linux package, I need to compile them myself. Download both, follow the setup directions, runmake. Get dependency errors. - Install
bison,pulseaudio-libs-devel, and the python 2 development packages. Rerunmake. - Try to use
SpeechRecognitionagain. Get a new error. I need thepocketsphinxPython package. pip install pocketsphinx. Fail due to missing dependencies. Installswig. Run again, find it’s missing a C header. Track down the source and installalsa-lib-devel.- Run
SpeechRecognition.Recognizer().record(). Wait for it to complete. - Drum fingers.
- Drum fingers.
- Drum fingers.
Hm, maybe trying to transcribe 30 minutes of speech at once was a bad idea. The lack of any progress indicators isn’t helping. Out of curiosity, I look up how much it would cost to transcribe it manually. While searching for that I find that AWS just released a new transcription service. It’s apparently pretty inaccurate, but hey, I don’t need quality for this.
At this point PocketSphinx has been running for 15 minutes. I leave it running and while I try out AWS.
AWS Transcription
- Upload the mp4 to an S3 bucket.
- Select it in the transcription service.
- Click “transcribe”.
- Download the transcription.
Total time, from discovering the service to getting the final file, is about 20 minutes. By this point Sphinx still hasn’t finished running.
The transcription file is a json with the following format:
{
job_name,
account_id,
results: {
transcripts: {
[{transcript}]
},
items: [{
start_time,
end_time,
alternatives [{}],
type
}]
},
status
}
The start time is per word, in seconds. The two item types are “pronounciation” and “punctuation”; we only care about the former. “Punctuation” items do not have a start_time field.
Since I have the start times per word, I don’t actually need the transcript itself. I can just extract the start times into an array and analyze that. There will be a few errors in the array, because the transcription gets some of the words wrong. At various points it transcribed “TLA+” as “Kelly Plus”, “Taylor Plus”, “till a plus”, and “Chile Plus”. But I don’t need it to be accurate. The talk is over 6,000 words long. It can add 300 extra words and still come under half my error budget.
Analyzing the Data
Choice of Language
I have two options for the data analysis.
First, there’s Python. Python is a workhorse. JSON parsing is easy and building out queries is straightforward. Python is my fallback language if I don’t have anything better to use.
The other option is J. I’ve complained about J before: it’s arcane and hard to express what you want to do in its ultra-terse language.1 I’d say I’m a low-end intermediate J programmer, so I’ll be able to do the analysis, but there’s not guarantee it will be any easier than Python. The big problem is going to be parsing the JSON. J is an array language: it’s designed to work with homogenous arrays. All elements of an array must be the same type, and all subarrays must have the same length. JSON, by contrast, is designed around heterogenous arrays, leading to an impedance mismatch.
On the other hand: I’ve had this idea for a while that J would make a good “interactive querying language”. It doesn’t matter if it’s hard to read if nobody else will ever read it. In fact, terseness is an advantage here. Compare writing
i = 1
for j in [x**2 for x in range(1, 20)]:
i *= j
to
*/ *: }. i.20
I wanted to explore this idea more, so picked J for this project.
Also, I like playing around with J. Sue me.
The Analysis
J can only store homogenous arrays. Every element of the array must have the same type and every subarray must be the same length. This makes it extremely difficult to store strings, let alone nested data! J uses boxing to get around this. A box can wrap any value, turning it into a single atom. This means the following two are the same type:
] x =: <'hello'
'┌─────┐
│hello│
└─────┘'
] y =: <1 2 3 ; 4 5 6
'┌─────────────┐
│┌─────┬─────┐│
││1 2 3│4 5 6││
│└─────┴─────┘│
└─────────────┘'
The dec_pjson_ library function converts the JSON string into a set of nested boxes. Dictonaries are represented as 2-column tables, where the first element is the key and the second is the value.2
dec_pjson_ '{"a": [1, 2], "b": {"c": 3}}'
'┌─┬─────┐
│a│1 2 │
├─┼─────┤
│b│┌─┬─┐│
│ ││c│3││
│ │└─┴─┘│
└─┴─────┘'
I can’t elegantly select by “key” here; it’s easier to select the corresponding table position instead. After that I need to filter out the punctuation items. I kludged out the first J script in about ten minutes.
require 'convert/pjson'
js =. dec_pjson_ fread 'codemesh-transcription.json'
match =: ;: 'type pronunciation'
lm =. -:&match@{:
p =. (#~ lm"2) > (2 1;1 1) {:: js
times =. ". > 1 {"1 0 {"2 p
I’m not going to explain how it works. It very roughly corresponds to the following Python version, which I wrote in about three minutes:
import json
with open("./codemesh-transcription.json") as file:
transcript = json.loads(file.read())
items = transcript['results']['items']
words = [float(i['start_time']) for i in items if i['type'] == 'pronunciation']
I expect J to be both faster and more concise than Python, but neither is true here. The Python script is only slightly longer than the J script. It also runs much faster, completing in less than a tenth of the time. Most of this time difference is due to dec_pjson_ being slow as heck.
Here’s where I made a mistake. I wanted to prove to myself that the J would be a lot terser if I could just reduce my character count more. This then consumed 2 hours of my life. I eventually got this:
require 'convert/pjson'
js =: dec_pjson_ fread 'codemesh-transcription.json'
t =. ". > (1&=&(L."0)#]) 0 1&{:: &.> (2 1;1 1) {:: js
Then I spent another hour trying to make it more “elegant”, and eventually reached this:
require 'convert/pjson'
js =: dec_pjson_ fread 'codemesh-transcription.json'
t =: ". 1 {::"1 ((<'start_time')&e."1 #]) ; (2 1;1 1) {:: js
Which is more elegant, trust me on this. It’s still much slower than the Python (still gotta decode the JSON). I spent even more time trying to optimize the runtime. That’s the big problem with J: it gets you obsessed with golfing.
I need to emphasize that this entire process was pointless. The 3 hour version didn’t get me better data than the version I wrote in ten minutes. That pokes a hole in my “J as a query language” idea.
On the other hand, I did learn a lot about how to better handle JSON in J… let’s get back to the transcriptions, shall we?
Analysis
Now that we have an array of numbers, J becomes a little easier to work with.
t is a list of all the times that I started saying a word, in seconds. The last time in the array is _1 {. t and corresponds to the total time I spent talking. The length of the array is the number of words I said, so divide the length by the last time will give my words per second. After that it’s just a multiplication to get my words per minute:
t
6.04 6.17 6.24 6.36 ...
wpm =: (60&*) @ (# % _1&{.)
wpm times
188.84
189 words per minute is already pretty fast, and it’s actually an underestimate. After I finished speaking there was five minutes of questions, which were less dense word-wise. If I want to get how fast I spoke during the talk itself, I need to filter out everything past the end of the talk, which was at 1920 seconds.
wpm 1920 (>#]) t
194.005
So about 200 words a minute. I also want to see how much this varies over time. To do that, I want to divide the times into bucket intervals, say 1 minute per bucket. I can do that by dividing each time by 60 and rounding down.
bucket =: <.@%~
t2 =: 60 bucket 1920 (>#]) t
That gives me, for each word, which bucket it falls in. Once I have that, I want to count how many words are in each bucket. Generating the minute counts (mc) is surprisingly easy in J, once you know the trick. First, we have u~ y ↔ y u y. Second, x u/. y partitions y into arrays using x as the keys, and then applies u to each partition. This means that u/.~ y will collect identical elements and apply u to all of them. For example:
1 2 1 </. 'abc'
'┌──┬─┐
│ac│b│
└──┴─┘'
</.~ 'aba'
'┌──┬─┐
│aa│b│
└──┴─┘'
{./.~ y would get the head of each partition. Since every element of the partition is is the same minute, this is equivalent to getting the corresponding bucket. #/.~ y counts every element of each partition, which is equivalent to the number of words that fall into that bucket. Finally, we stitch the two arrays together with ,..3
] mc =. |: ] ({. ,. #)/.~ t2
0 1 2 3
197 196 186 195 . . .
As a sanity check, we should get the average of the wpm and make sure it’s close to our old value. I also recall the standard deviation as being “the square root of the mean of the differences of the values and the mean squared”, which is a lot easier to express in J than it is to express in English. We use the “under” operator &.:: if *: means “square”, then f&.:*: y ↔ sqrt(f(y^2)).
mean =: (+/%#) 1 { mc
mean ; (+/%#)&.:*: mean - (1 { mc)
'┌───┬───────┐
│194│13.5254│
└───┴───────┘'
They’re about the same, meaning that we’ve got it mostly right.
J comes with a built in plot library called, creatively enough, ‘plot’.
require 'plot'
r =: 1 { mc
plot r ,: 0
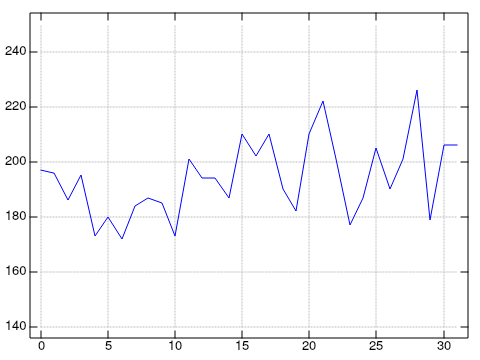
That’s a peak speed of over 220 words per minute. I need to slow down.
Slowing Down
How do I slow down? Same way I do anything: practice.
When I’m trying to speak slowly and carefully, I slow down by about a third, to roughly 130 wpm. That’s my first target: practice saying something at 130 wpm. Let’s grab an arbitrary paragraph of text:
I speak very fast. It’s like the words are piled up in my mouth and I can’t say one without the rest tumbling out. Through my whole life people have told me to slow down, speak more clearly, and enunciate. I can do it if I concentrate but I quickly relapse into gushing out words.
That’s 55 words. At my normal conference rate, I’d say that in 16 seconds. At 130 wpm, it’d be 25 seconds. I practiced saying that with a stopwatch and quickly found out that saying that in 25 seconds is just awful. Anything past 20 seconds and it feels like I’m just aiming for the metric instead of clarity. At 20 seconds, that’s 165 wpm.
Is 130 wpm too slow? I don’t think so. The problem here is that speech isn’t uniform. A speech has pauses, meaningful silence, quotes, points you rush for emphasis, etc. I want to hit 130 wpm on average, not for every single thing I say. Some things might be faster, some might be slower. The smaller the rehearsal sample, the less likely that it’s a representative sample. 260 words, or about 2 minutes, seems like it would be more representative. I took a talk draft, made several two-minute chunks, and spent some time each day practicing them. After a while I could comfortably hit 130 wpm. After that, I added this to my vim config:
function! g:Exo_vwal()
let s:worddict = wordcount()
if has_key(s:worddict, "visual_words")
return s:worddict["visual_words"]
else
return s:worddict["words"]
endif
endfunction
" Extraneous stuff removed
au BufNewFile,BufRead *.talk.md setlocal statusline+=/%{g:Exo_vwal()/130}
Now, when I open a file of filetype .talk.md, it shows the expected length of the talk in the status bar. If I visually select a snippet, I can also see how long that particular snippet takes. I still need to rehearse the talk to get the actual time, of course, but it’s a good first-order estimate. I can look at a section and immediately see if it’s roughly the right length or not.
Results
This was all in preparation for What We Know We Don’t Know, my talk on empiricism in software engineering. That talk felt easier on me, but I wanted to confirm I really was speaking more slowly. Once the video went online, I transcribed it and did the same analysis:4
mean ; (+/%#)&.:*: mean - (1 { mc)
'┌───────┬───────┐
│162.816│25.1771│
└───────┴───────┘'
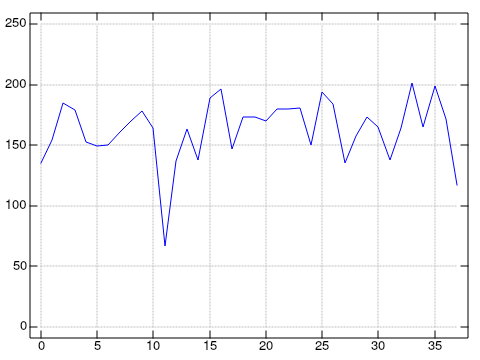
It looks like the previous graph, but the y-axis is different. My mean is 162 wpm. It might not be 130, but it’s much better than 194. The deviation is much higher than before, but that’s expected, as I varied this talk’s tempo. Finally, I maxed out at 201 WPM, unlike before, when I hit 221 WPM. Here’s a graph of both together.
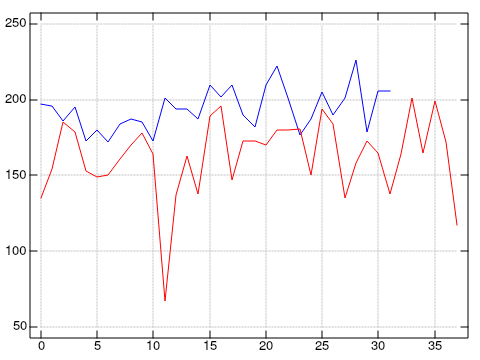
My latter talk was about 6 minutes longer. What surprised me, though, was that the two talks covered the same amount of content. They both were around 6000 words total. That makes the whole analysis feel more “feasible” to me. Slowing down is easier on both me and the audience, but it doesn’t come at the cost of information.
Takeaways
Overall I’m glad I did this project. It gave me useful information that materially improved my speaking skills. I still need to regularly practice pacing, as otherwise I’ll slip back to 200 WPM.
Other takeaways:
- Automated transcription is cheap if you don’t need accuracy.
- It’s feasible to introspect the way I do things and then use that information to do them better.
- J isn’t the data querying tool I hoped it’d be.
- Rehearsing is good.
Thanks to Alex ter Weele for feedback.
- I’m going to assume a tiny bit of knowledge of J. If this is your first encounter, I have some more beginner-friendly articles here and here. [return]
- This means
dec_psjon_isn’t compliant with the JSON spec: if you have a duplicate key, it will create two rows. [return] - When editing this post I wondered why I was creating the first row, because I never actually used it. It’s because we might have a minute with no words in it at all! Without the first row, we have no way to knowing if this happened. With the first row, we’d see a gap in the incrementing numbers. In practice, though, there weren’t any gaps. Commenting your decisions is a good idea! [return]
- This took me over 30 minutes to redo. First, I forgot how to import files in J, and then processing the file wasn’t working. After 15 minutes of searching, I discovered I had written
&e."1instead of@e."1. J I love you but you’re killing me here. [return]