Formally Modeling Database Migrations
Most of my formal methods examples deal with concurrency, because time is evil and I hate it. While FM is very effective for that, it gives people a limited sense of how flexible these tools are. One of the most common questions I get from people is
Formal methods looks really useful for distributed systems, but I’m not making a distributed system. Is FM still useful for me?
Instead of a distributed system, we’re going to do something different. Lots of business apps store their conceptual model in a relational database. If you need to change the structure of the data, you need to convert all of the stored data to the new format. This is a data migration. Migrations are risky business because they involve changing a large amount of state at once. They’re also often irreversible, and if something goes wrong you cannot easily undo the migration.
We’d like to make sure the migration will be safe, or that it will accurately map all of our data to the new format. We also want to make sure that the new format matches our requirements. If we accidentally lose a database constraint, then the migration might go fine but we might later become inconsistent.
Modeling a migration is a four-step process. First, we specify the old data representation and the new one. Then, we define what it means for data in each representation to be “equivalent”, in terms of having the same information. Third, we show that equivalent data will have the same constraints: it’s impossible for old data to satisfy the old schema’s constraints but be equivalent to something that violates the new schema’s constraints. Finally, we specify the migration and show that migrated data is equivalent to the old data.
We’re going to use Alloy for this. Alloy is very good at specifying relationships between entities, whether it’s the relationships between tables in a schema or the relationship between two separate schemas. It can also create create visual diagrams of its models, which is handy for exploring your specs. This essay assumes no prior Alloy knowledge. If you want to follow along, you can download it here.
The Problem
Our system has People and Events. People attend events and either like or hate them. As a database constraint, we want to enforce that a person cannot both like and hate the same event. For simplicity we’ll assume you don’t have to attend an event to like or hate it.
In our original system, we had two tables, a Person table and an Event table. We modeled the relationships as three separate columns on the Person table, each column a set of Event ids.1
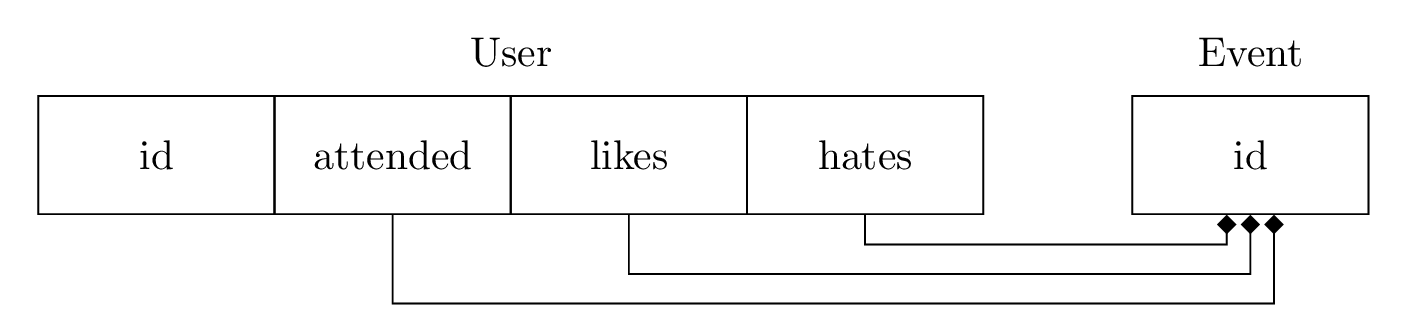
For our new system, we want to replace the three columns with two tables: an Attendance table and a Review table. Each of them stores both a Person id and an Event id. Review will also store whether the review is “like” or “hate”.
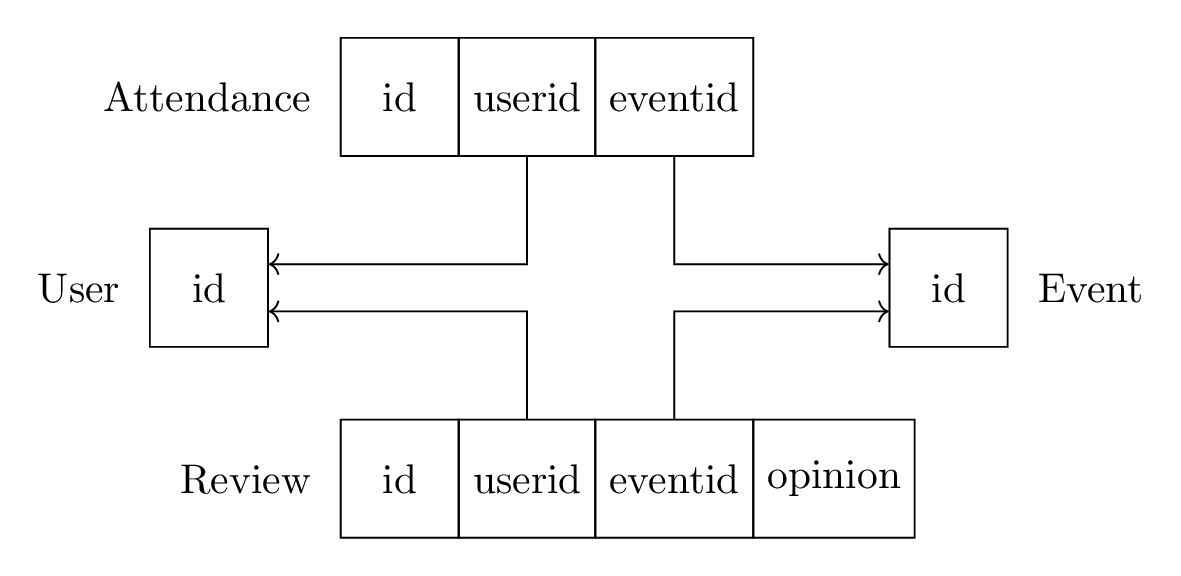
Our system already has data in it. We need to migrate all of that data to the new format. Going forward, we also want to preserve the same constraint, where you can’t both like and hate the same event.
The Model
Old Schema
sig Event {}
Event is a signature. This specifies the types of instances, or atoms, in our model. To keep things simple, the event doesn’t have any other information associated with it. This alone is a complete model, and Alloy can generate matching examples:
Now we add people:
sig Person {
events: set Event,
likes: set Event,
hates: set Event
}
The body of the signature consists of three relations. Relations relate things. Every Person “has” a set of Events they attended, a set they liked, and a set they hated. The set means there are no constraints on just how many events are in each. There are several other quantifiers, like some (at least one) and lone (zero or one).2 Now Alloy can generate considerably more complex models:
The Alloy visualizer has a lot of features for analyzing these diagrams, such as an expression evaluator and theming. I can distinguish the shapes and colors of the different signatures and change how the relationships are rendered:
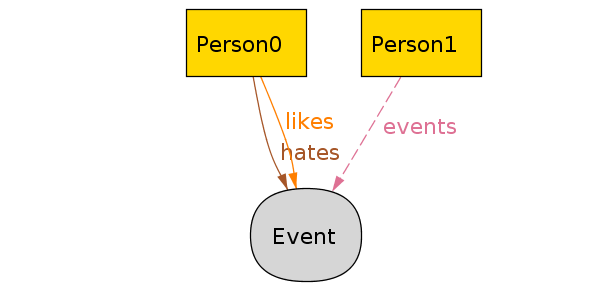
You can download the theme I used here if you’re following along.
Next, we need to express the constraints. No person should like and hate the same event. We can express that with a predicate, or a boolean function:
pred valid[p: Person]
{
no p.likes & p.hates
}
Our only constraint in this example is there is no intersection (&) between these two sets.
Not all generated models will be valid. This is intentional: we want to both be able to say that a certain model satisfies our requirements, and also that one doesn’t satisfy our requirements. We could tell Alloy to only generate valid instances of Person by adding a runtime predicate:
run {all p: Person | valid[p]}
New Schema
For the new schema, we want separate instances for attendance and reviews. To make things easier, we’ll create a NewPerson signature that points at an existing Person.
sig NewPerson {
, person: one Person
}
We could also leave out the one here, as Alloy defaults to one if we don’t specify a quantifier. Now for the new tables:
sig Attendance {
event: Event,
attendee: NewPerson
}
abstract sig Review {
event: Event,
reviewer: NewPerson
}
sig Likes, Hates extends Review {}
Review is abstract. We cannot have an instance that is just a Review, we can only have the subtypes in the model. So every Review will either be a Likes review or a Hates review. Both, however, still count as a Review, meaning the set of all Likes is a subset of the set of all Reviews.
Finally, we should write a version of valid for NewPerson. For the sake of instruction later, I’m going to make it always true:
pred valid[p: NewPerson] {
some p
}
We have two valid predicates, one for Person and one for NewPerson. Alloy sees these are distinct types and has no trouble handling the overload.
Showing Equivalence
What does it mean for a NewPerson to be equivalent to the original Person? In this case, we can say that they’re equivalent if
- They have the same events
- They have the same likes
- They have the same hates.
Let’s start with the first case:
pred same_events[p: Person, np: NewPerson] {
p.events = ???
}
How do we get all the events that the NewPerson attended? The data exists on the Attendance instance, not the NewPerson! Here’s where Alloy’s model really shines through. Attendance “has” an attendee relation. This is actually a first-class entity! Alloy sees attendee as a mapping from Attendance instances to NewPerson atoms. We can manipulate the relationship itself. One way is by using ~, which reverses a relation: ~attendee maps each person to their attendance records. As a visual example:
attendee
~attendee
| from | to |
|---|---|
Attendance1 |
Person1 |
Attendance2 |
Person1 |
Attendance3 |
Person2 |
| from | to |
|---|---|
Person1 |
Attendance1 |
Person1 |
Attendance2 |
Person2 |
Attendance3 |
-- a NewPerson
np
-- every Attendance record for a NewPerson
np.~attendee
We can also apply relationships to sets of atoms. Attendance is the set of all attendance atoms. Attendance.event is the set of all events that were attended by anybody. Then np.~attendee.event would be all of the events attended by the specific np.
pred same_events[p: Person, np: NewPerson] {
p.events = np.~attendee.event
}
For same_reviews, we can do something similar. np.~reviewer is all of the reviews by a specific np. This includes both positive and negative reviews, which we need to distinguish. We can do this with a set intersection. Likes is all of the positive reviews, so np.~reviewer & Likes is the set of all positive reviews by np. Finally, (np~.reviewer & Likes).event is the set of all events that correspond to positive reviews by np. We get the negative reviews in a similar way.
pred same_reviews[p: Person, np: NewPerson] {
p.likes = (np.~reviewer & Likes).event
p.hates = (np.~reviewer & Hates).event
}
We have two clauses in this predicate. All statements in the curly braces must be true for the entire predicate to be true. Between same_events and same_reviews, we have enough to check whether a given Person and NewPerson represent equivalent data:
pred equivalent[p: Person, np: NewPerson] {
p = np.person
same_events[p, np]
same_reviews[p, np]
}
We use the same multiple clauses here: all three clauses must be true for equivalent to be a true predicate. Let’s generate a matching example:
example: run {
one Person
one NewPerson
equivalent[Person, NewPerson]
}
By default Alloy will run the topmost run in your spec. You can select which one to run from the Execute menu.3
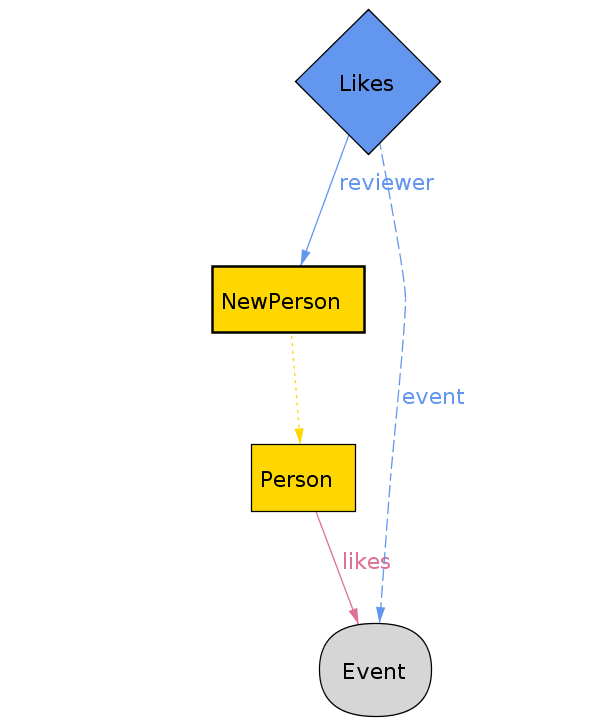
Validity Equivalence
Before we can spec out the migration, we need to do two things. First, we need to show that the two models can express equivalent data. That part’s done. Second, we need to show that the new models have equivalent constraints. If a Person violates our constraints, so should the equivalent NewPerson. If the former satisfies the constraints, the latter should also satisfy the constraints. We need to assert that two equivalent models have equivalent validity.
assert equivalence_preserves_validity {
all p: Person, np: NewPerson |
equivalent[p, np] implies (valid[p] iff valid[np])
}
If the two data models are equivalent, then they are either both valid or both invalid. As we didn’t actually put any constraints on NewPerson, we should expect this assertion to be false. By telling Alloy to check it, Alloy will search all possible models to see if any break this.
check equivalence_preserves_validity
Unsurprisingly, Alloy finds a counterexample:
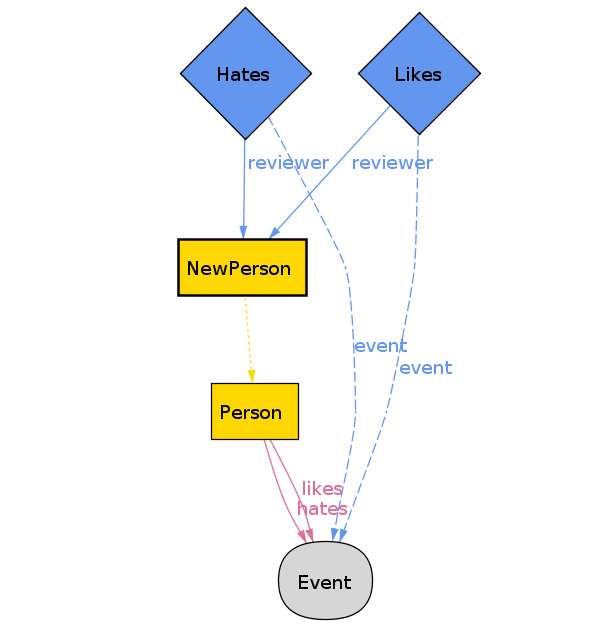
Both Person and NewPerson attended the same event, and they have matching likes and dislikes. That means they’re equivalent. However, Person likes and hates the same event, which means Person is invalid. But NewPerson is still valid, breaking our assertion. To fix this, let’s add another constraint to valid[np: NewPerson].
pred valid[np: NewPerson] {
all r1, r2: np.~reviewer |
r1 in Likes and r2 in Hates
implies r1.event != r2.event
}
In English: For any two reviews done by np, if one is a Like review and the other is a Hates review, then they must belong to different events. Once we update the definition of valid, Alloy finds no more counterexamples.
It’s worth emphasizing the scope of the model checker. Unless specified otherwise, Alloy will assume up to three instances of each signature may be present. For three events and one p: Person, there are 8 possible values for p.events and 64 possible values for p.likes and p.hates. There are at least as combinations of Assignment and Review for np: NewPerson, meaning that, as an extreme lower-bound estimate, Alloy is checking 2^18 possible examples.4 On my computer, Alloy sweeps the state space in just a few milliseconds.
Modeling the Migration
Now we’re ready to model the migration itself. While the equivalence predicate is declarative, the migration needs to be more algorithmic. Someone looking at the migration should easily be able to translate it to code.
In a programming language, we’d write a function that transforms a Person into a NewPerson. While Alloy has functions, they’re not useful here. In specifications, we don’t restrict ourselves to a single model, and instead talk about the entire space of possibilities. Instead, we specify what it means for a NewPerson to be a migration of a Person and let Alloy explore the models where that relation holds.
pred migration[p: Person, np: NewPerson] {
p = np.person
-- migrate events
all e: p.events |
one a: Attendance {
a.event = e
a.attendee = np
}
-- migrate likes
all l: p.likes |
one r: Likes {
r.event = l
r.reviewer = np
}
-- migrate hates
all h: p.hates |
one r: Hates {
r.event = h
r.reviewer = np
}
}
Somebody could look at this and know what they have to do: take the events column on each Person row and, for each element in that column, create a corresponding row in the Attendance table. Do the same with likes and hates. That’s all.
If this is a correct description of the migration, then our migrated data should be equivalent, right?
assert migration_preserves_equivalence {
all p: Person, np: NewPerson |
migration[p, np] implies equivalent[p, np]
}
check migration_preserves_equivalence
Alloy finds a counterexample!
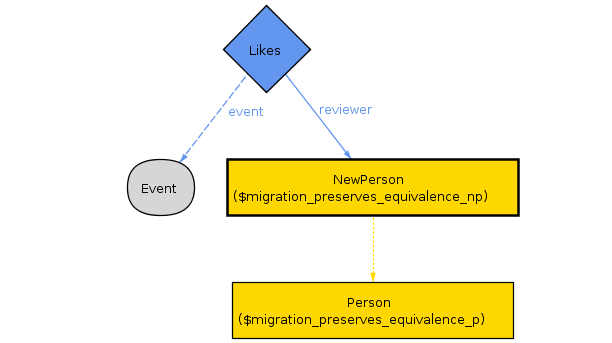
What’s going on here? We created exactly one corresponding Like for every event that Person liked. Since Person didn’t like any events, we needed to create zero corresponding rows for NewPerson. This is satisfied, so the migration predicate is true. We also, for unrelated reasons, created an unrelated Like for NewPerson. This means they’re not equivalent. So we have relationship that counts as a migration but does not preserve equivalence.
In other words, we didn’t constrain the migration rules enough. You could “create” the corresponding rows in the new schema just by adding a row for every event in the database! What we actually need to say is “for each and only the elements in the column, create the corresponding row.”
-- migrate events
all e: p.events |
one a: Attendance {
a.event = e
a.attendee = np
}
+ no e: Event - p.events |
+ some a: Attendance {
+ a.event = e
+ a.attendee = np
+ }
This is getting a bit unwieldy, so let’s simplify it by instead saying that we create exactly as many rows as are in the events column:
pred migration[p: Person, np: NewPerson] {
p = np.person
+ -- only generate the records needed
+ #p.events = #np.~attendee
+ #p.likes = #np.~reviewer & Likes
+ #p.hates = #np.~reviewer & Hates
The # means “number of elements in the set”. With this change the assertion now passes. We have shown that migrations produce equivalent models, and equivalent models have equivalent validities.
We could stop here. But there’s a couple of additional tricks we have. First, if we want to be thorough, we should check some statements that we expect to be correct. Alloy makes it very easy to “battle test” our specifications this way. If we can express a property of the spec, we automatically have the complete test for it. Second, we can check some properties where we don’t know if they should be correct or not. Alloy will generate examples that give us more insight into our system.
Being Thorough
Here’s a property I’m uncertain of: if two data models are equivalent, is one of the migration of the other?
assert equivalence_implies_migration {
all p: Person, np: NewPerson |
equivalent[p, np] implies migration[p, np]
}
check equivalence_implies_migration
This property does not hold:
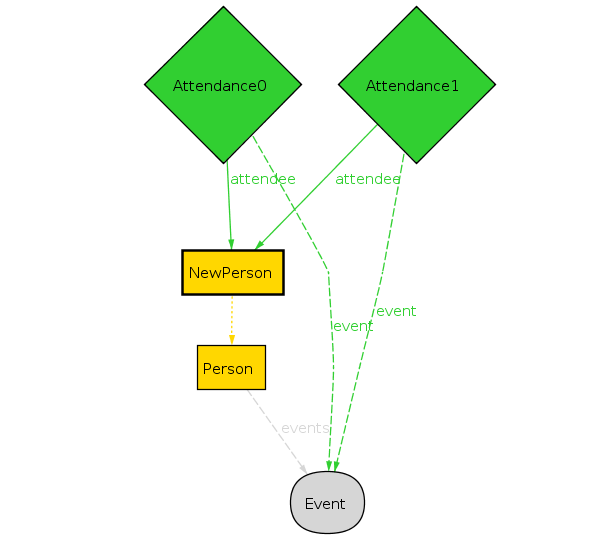
The NewPerson is equivalent to the Person. We have the same events liked and attended. But we have two database records for liking the same event! Now, this might not actually be a problem. Our new data model is considerably richer than our old one, so it makes sense that we can express something that the old model could not. It’s our decision whether having multiple review or attendances of the same type is a valid use case. If it’s not a valid case, we can patch this by changing our valid predicate for NewPerson:
pred valid[np: NewPerson] {
all r, r': np.~reviewer |
r in Likes and r' in Hates implies r.event != r'.event
+ all e: Event {
+ -- at most one review for this event
+ lone r: np.~reviewer |
+ r.event = e
+
+ -- at most one attendance
+ lone a: np.~attendee |
+ a.event = e
+ }
}
This doesn’t fix equivalence_implies_migration. Not only that, but it also breaks equivalence_preserves_validity. We’ve made the NewPerson constraints stronger without changing the corresponding Person constraints. There is now an invalid NewPerson that are equivalent to a valid Person.
There’s also a valid NewPerson equivalent to the valid Person, which is why equivalence_implies_migration breaks. We could have migrated to an invalid NewPerson or a valid NewPerson. Patching that property is easy enough.
assert equivalence_implies_migration {
all p: Person, np: NewPerson |
- equivalent[p, np] implies migration[p, np]
+ (equivalent[p, np] and valid[np]) implies migration[p, np]
}
Dealing with equivalence_preserves_validity is harder. The “obvious” way to fix this is to modify equivalent. This would be a mistake, though. Right now equivalence is purely definitional: we are taking the data in NewPerson and translating them into equivalent statements for Person. It does not restrict how we define NewPerson, or the constraints we placed on it. Changing equivalent would mix our abstraction levels.
We’re better off reexamining our assertions.
Rethinking Our Properties
Here are our three properties:
- Migrations produce equivalent schemas
- If two valid schemas are equivalent, they must have been produced by a migration
- Equivalent schemas have equivalent validities (broken)
Consider our actual system. Assuming everything is “normal”, we already know all of the existing data is valid. We then migrate, which converts every instance to its equivalent in the new schema. The migration will fail if we accidentally convert valid data to invalid data. Finally, going forward, all data will be in the new schema. We should not be able to update it in a way that would correspond to an invalid data in the old system. With that in mind, we have the following properties as our requirements:
- Migrations produce equivalent data
- If two valid schemas are equivalent, they must have been produced by a migration
- If the new data is valid, then the equivalent old data would have been valid, too
- If we have valid old data and migrate it to the new schema, the new data will also be valid
We’ve split property (3) into two weaker properties. The original one isn’t something we can guarantee anymore, but the two weaker properties can be guaranteed. This means our assertions become:
- assert equivalence_preserves_validity {
- all p: Person, np: NewPerson |
- equivalent[p, np] implies (valid[p] iff valid[np])
- }
- check equivalence_preserves_validity
assert equivalence_does_not_decrease_validity {
all p: Person, np: NewPerson |
equivalent[p, np] and not valid[p] implies not valid[np]
}
assert migrations_stay_valid {
all p: Person, np: NewPerson |
migration[p, np] and valid[p] implies valid[np]
}
check migrations_stay_valid
check equivalence_does_not_decrease_validity
All properties are now preserved and we have verified our migration. You can see the entire spec here.
Discussion
The above example only used a fraction of Alloy’s functionality. We can express much more complex migration properties than this, such as multistage migrations, rollbacks, or complex transformations. At the same time, we’ve seen almost all of Alloy’s syntax. The entire grammar is less than two pages. That’s roughly the same length as the simplified JSON grammar. Alloy packs a lot of power in a very small space.
We’re currently writing online documentation for Alloy, but in the meantime the best place to learn is the book Software Abstractions. If you’re interested in learning of other applications, Jay Parlar had an excellent talk at StrangeLoop this year. Finally, if you’re interested in using Alloy at your job, I run workshops. You can contact me here to learn more.
Thanks to Jay Parlar and Richard Whaling for feedback.
- You can download the source code for the schema images here. [return]
loneis short for “less than or equal to one”. [return]- If you’re following along, you may see a different model. Alloy uses a SAT solver to find solutions and different machines may present solutions in a different order. [return]
- In practice, many of these states are symmetrical with each other, meaning iff one’s valid, they’re all valid. Alloy is very smart about pruning the possible state space. [return]