This is How Science Happens
I love science. Not the “space is beautiful” faux-science, but the process of doing science. Hours spent calibrating equipment, cross-checking cites of cites of cites, tedious arguments about p-values and prediction intervals, all the stuff that makes science Go. And, when it does happen, the drama. I also want us to use more empirical science in software. That’s why I wrote a talk on it!
One thing lay folk don’t realize is that science is social. For all we focus on “objectivity” and “evidence”, it takes place in human institutions and relies on how humans work. We care about integrity, trustworthiness, and reputation. While this often surprises outsiders, it’s ultimately necessary for science to work in the large.
Which is why I find the following such a good introduction to why this all matters:
There’s a lot of entertaining background here. Even better, the drama shows us much about how research happens, the pitfalls people face, and how scientists might not be the best at gracefully receiving criticism. And, ultimately, just how much the process of science is embedded in a social institution, just like everything else we do. 1
Disclaimer: I’m not a neutral party here, as the first part of this debate features prominently in my talk on Empirical Software Engineering (ESE) and I picked a side. I eventually ended up reviewing a draft of the Replication Rebuttal Rebuttal. Finally, Emery Berger answered some technical questions for me, but he had no input on this essay and has not seen any of the drafts. I’ll try my best to be impartial, but there’s no guarantees I succeeded.
I’m also going to be omitting some content in these papers to focus on the science narrative. You should read them all for the full story- they’re pretty accessible for academic papers.
Background
How much does your choice of language affect your program’s defect rate? In theory, we’d expect it to have at least some impact. Some languages care much more about correctness than others. Most people would assume that Rust would have fewer memory errors than C, or that Haskell would have fewer type errors than JavaScript.
In practice, this is very difficult to study. There are lots of factors affecting our code quality, everything from tooling to team structure to type of project. People sometimes go too far and say that it’s straight-up impossible to study programmers. I wouldn’t go that far: doctors and teachers make the exact same arguments, and we’ve found that we can study both of those fields just fine. But it’s still very difficult and takes a lot of money and time to get answers.
As far as we can tell, factors like sleep and psychological safety matter much more for productivity than any technical decisions. This doesn’t mean that language doesn’t matter at all; just that we haven’t yet been able to find a strong signal it does matter, while we’ve found strong signals that social factors do. But it still seems intuitive that language should matter. If the effect is small but significant, we need a lot more data to find it.
To get a lot more data, some groups have turned to repo mining. GitHub has over 100 million repos in a wide variety of languages. If we could find ways to accurately extract data from GitHub, then we can compare and contrast languages on a large scale. The downside is that the GitHub data is very noisy: if I search “bug”, I get insect animations. In order to make GitHub mining useful you need to very, very carefully separate the signal from the noise.
This is a story of what happens when you don’t.
November 2014
Premkumar Devanbu, Vladimir Filkov, and others publish Large Scale Study of Programming Languages and Code Quality in GitHub at the Foundations of Software Engineering conference. I’ll refer to it as the FSE paper.
They wanted to see if certain languages, or classes of language, lead to more defects than others. While other papers have tried to study sets of codebases before, the FSE paper was the first notable paper to use GitHub. They took git repos and searched the commits for messages about fixing a defect. They called these Defect-Fixing Commits, or DFCs. Assuming each DFC corresponds to a single bug, the number of DFCs vs regular commits is a rough measure of how “buggy” the project is.
Many things affect this number: size of project, number of developers, project culture, etc. The authors were interested in knowing how much the project language affects the DFC count. This makes everything else a confounding factor. By looking at a large number of projects, they could control for these factors. The more factors you need to control for, the more projects you need to look at. This where GitHub comes in. FSE mined 729 projects, representing over 80 million lines of code in 17 languages. With all this information, they could see how much each factor affects the defect rate.
Results
The biggest factor was, unsurprisingly, number of overall commits. The more commits you make, the more absolute DFCs you’ll make, too. This is a table about how much each contributes:
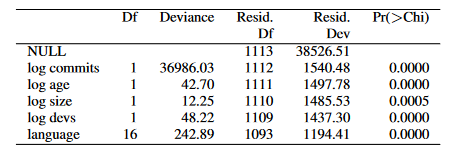
Deviation is how much this affects the results- higher means it affects things more. About 99% of the deviance comes from log(commits).2 As a very rough rule of thumb, they’re saying if two codebases have different DFC rates, about 99% of the difference is due to commit rates. About 0.6% is due to choice of language, and 0.4% is due to everything else. In other words, if you pick two random codebases and one has significantly more DFCs than the other, it’s much more likely that they have different commit rates than that they have different numbers of committers.
This is different from the actual predictive effect. “How much of the difference between projects is explained by choice of language” is a different question from “How much does choice of language change the amount of DFCs”. Here’s the predictive effect of languages:
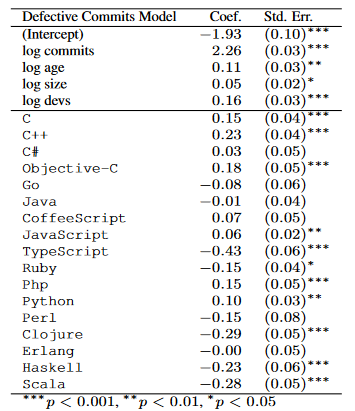
If a project would have N DFCs normally, then an equivalent project where everything was the same except the language would have Neᵝ DFCs. In other words, if “a particular project developed in an average language had four defective commits”, then the equivalent codebase in C++ would have 5 and the Haskell codebase would have just over 3. TypeScript, by comparison, would have about 2.6. If you instead held language constant and tripled-ish the number of commits, you’d see approximately 38 DFCs.3 As the FSE authors put it:
Most notably, it does appear that strong typing is modestly better than weak typing, and among functional languages, static typing is also somewhat better than dynamic typing. We also find that functional languages are somewhat better than procedural languages
They’re underselling the effect here. While the dominant factor is number of commits, language still matters a lot, too. If you choose C++ over TypeScript, you’re going to have twice as many DFCs! That doesn’t necessarily mean twice as many bugs, but it is suggestive. Further, while they say the effect is “overwhelmingly dominated by […] project size, team size, and commit size”, that doesn’t actually bear out. Only the number of commits is a bigger factor in language choice.
There are some other claims in this paper, primarily in trying to classify language impacts by type of bug, but I’m going to focus on just the defect rate for this essay.
November 2014
Science is a social process. It’s not enough to be right, you also have to be convincing. Regardless of how good your work is, if you sound like a crank nobody will believe you.
Part of being convincing is being clear about the limits of your work. Nobody can handle every confounding factor. Any good paper will mark out its problems, or threats to validity. The FSE paper listed three major threats to validity: one, using keywords in commits over “official” bugs in an issue tracker; two, judgement calls on classifying the types of languages; three, associating defect commits to language properties instead of reporting style or project culture.
Dan Luu, in his phenomenal piece Static v. Dynamic languages, found one more:4
As for TypeScript, the three projects they list as example TypeScript projects (bitcoin, litecoin, and qBittorrent) are C++ projects. So the intermediate result appears to not be that TypeScript is reliable, but that projects mis-identified as TypeScript are reliable. Those projects are reliable because Qt translation files are identified as TypeScript and it turns out that, per line of code, giant dumps of config files from another project don’t cause a lot of bugs. It’s like saying that a project has few bugs per line of code because it has a giant README. This is the most blatant classification error, but it’s far from the only one. Since this study uses GitHub’s notoriously inaccurate code classification system to classify repos, it is, at best, a series of correlations with factors that are themselves only loosely correlated with actual language usage.
This is a very serious issue. Some kinds of mistakes have limited impact, affecting one part of the paper but not the overall conclusion. This affects everything. You can’t say anything about the defect-proneness of TypeScript if the project isn’t actually in TypeScript.
There are also social consequences to this kind of mistake. It means they were sloppy. Bitcoin is obviously not TypeScript. If they missed the obvious error, they probably also missed subtle errors. By making this mistake, the authors become less trustworthy. Not untrustworthy, but we become more inclined to be skeptical of anything they say. Even if they publish a corrected version, there could be other mistakes they missed, or even mistakes in the correction itself! They have to go “beyond the zero” to reestablish trust: not just fix the errors, but show that they’ve fixed the forces that caused the errors. For example, they could also show that none of the other 700+ projects had the wrong language, too.
October 2017
The FSE authors publish Large Scale Study of Programming Languages and Code Quality in GitHub in the Communications of the ACM magazine. Going forward, I’ll refer to the “CACM authors” and the “FSE authors” interchangeably.
The CACM paper was an expanded, “archival” version of the FSE paper.5 The authors didn’t list the differences between the two versions, but we can compare them to work out what changed:
- TypeScript projects are actually TypeScript.
- Language choice now explains about 0.5% of the total deviance.
log(commits)is no longer the dominating factor, though, and only explains 18% of the total deviance. The biggest factor is nowlog(size), at 42% of the deviance.6 - All the other factors, except
log(devs), have lower prediction power.
Not all that difference can be explained by them just classifying languages better. It turns out they also made a calculation error. When people write log(x), they usually mean “log base e”, or the natural logarithm: log(100) ~= 4.6.7 To increment log(x) you’d have to triple-ish x. However, some people write the natural log as ln and use log to mean “log base 10”: log(100) = 2. And some of those people instead use base 2, so log(100) = 6.6! It’s a really bad idea to use log without writing the base. The authors accidentally mixed ln and log10 for log, leading to a bunch of miscalculated results. This is also why, incidentally, the prediction power of log(commits) was different in tables 6 and 7 of the FSE paper.
Fixing everything pushed the predictive effects closer to each other. This makes language impact predict more than it did before. The authors again cautioned that the effect is small and people should be skeptical that there’s a true link. This is correlation, not causation.
People still took it as causation. According to Google, the FSE and final versions have been cited over 200 times, making it a very influential paper in its field.8 Left alone, this paper would have been regularly cited as solid evidence of a link between language choice and code defects.
Then something very strange happened.
The paper got replicated.
Replication
Don’t trust anything that’s not replicated.
If an effect exists, it should be observable by anyone in similar conditions. This is one of the core foundations of empirical science: all claims should be replicated by a third party. If something doesn’t replicate, then the effect is more limited than we expected, or there was an implicit assumption in the original experiment, or somebody made a mistake somewhere.
In an ideal world, we’d try to replicate all papers. But replication is an expensive process and there’s very little prestige in doing it. Academics have a lot of trouble getting replications published, even when they contradict the original experiment. This means that people only replicate when it’s likely to be interesting. This means looking for signs that the replication will give additional insight into the original claim.
In this case, the sign was this:
On a closer look, we find that JavaScript has only one project, v8 (Google’s JavaScript virtual machine), in Middleware domain that is responsible for all the errors…
V8 is in C++.
This might not be an error. While V8’s core engine is in C++, it also has a lot of JavaScript, too. But it suggests the FSE authors didn’t audit all the projects after the TypeScript mistake. All they did was fix TypeScript. It’s not as big a deal as mistaking bitcoin for TypeScript, but it’s still a sign that something is off.
Replication is the core of the scientific method, and it’s a widely recognized problem that it’s fallen by the wayside. Which is why it was so surprising to see any paper get replicated, and in particular this paper, and in a way that so clearly and painfully shows us why we need to replicate in the first place.
April 2019
Emery Berger, Jan Vitek, and others publish On the Impact of Programming Languages on Code Quality: A Reproduction Study in the Transactions on Programming Languages and Systems journal. Going forward, we’ll call it “TOPLAS”, or the “replication”.
Berger et al. started with a partial replication of CACM. They emailed the CACM authors, received the data dump, and got to work. At first, they had the following goals:
- Rerun the analysis and see if they got the same result.
- Approach the same dataset with different statistical methods and see if they got the same result.
- Fix any statistical issues in the original paper.
A Note on P-values
Disclaimer: the following discussion of p-values is currently inaccurate and I’m looking into how to improve it. See update, below.
If you’ve read any research studies or listened to arguments between statisticians, you’ve probably seen p-values. So what is a P-value, anyway?
The P-value is the probability that you would have seen the same result if the hypothesis wasn’t true, purely due to other factors. Let’s say I flip a coin that might be double sided and get heads. The chance the “null hypothesis” could have explained this is P = 0.5. If the coin is not biased, I would have gotten the same result 50% of the time anyway. If I flip the coin ten times and get heads each time, then I have P < 0.001. There’s only a 1 in a 1024 chance that a completely unbiased coin would have gotten the same result.
P-values are easy to calculate, but they have so many pitfalls that the American Statistical Association warns against them. One problem is that the P-value is only the probability that a “coincidence” could explain the data. It doesn’t give us any insight into whether our specific claim is correct. I flip a coin and get ten heads in a row, I can’t statistically conclude the coin is double-sided, only that it’s unlikely to be entirely unbiased. A double-sided coin explains the result, but so does a 90% bias.
Another big problem is deciding the cutoff. How low does the P-value need to be before we can be confident in rejecting the null hypothesis? Most fields of research have arbitrarily chosen 0.05 as the cutoff. Anything below that is significant, any value above that is not significant. But not always. Particle physics, for example, uses a cutoff of P < 0.0000003. If they just went with the 0.05 convention they’d get millions of spurious results.
Even if 0.05 is good for your purposes, you need to adjust the cutoff if you’re testing multiple different hypotheses. The FSE authors checked 17 different languages. At 0.05 significance there’s a 60% chance that at least one of their measurements is a false positive and a 15% chance that two or more were false positives. You need to use “Multiple Hypothesis Correction” to return to the baseline. There are multiple ways to do MHC. The simplest, called Bonferroni, would just be dividing the cutoff by the number of hypotheses. In this case, the new cutoff would be 0.003. Simple.
That’s if you don’t have any other issues. But then Berger et al. started digging into the data. There they discovered some bigger problems.
Bigger Problems
You might have noticed that in the FSE paper, they listed Bitcoin and Litecoin as studied projects. Litecoin is a fork of Bitcoin. They share approximately 18,000 commits in common. If you counted a DFC in both projects, you would actually be counting the same commit twice.
TOPLAS found out that approximately 2% of the dataset were duplicate commits. This wouldn’t be such a big problem if the duplicates were evenly spread out, it’d just be another source of noise. But the duplicates weren’t evenly spread out: the dataset included seventeen forks of bitcoin. Over 10% of the studied C++ projects were bitcoin forks.9
FSE had other classification issues. They counted V8 DFCs as JavaScript defects, not C++. Their TypeScript files were mostly irrelevant configs, even after the first round of corrections. To get good data, TOPLAS had to drop TypeScript entirely. And “the number of devs” control was completely off: they were actually controlling for number of pull request authors, which leaves almost 40% of the actual devs out.
Originally, FSE tested 17 languages and found 11 of them had a statistically significant impact. TOPLAS, after applying all the dataset corrections, only found five of them were significant. Applying the multiple-hypothesis correction dropped that number to four.10
After all that, though, they discovered an even bigger problem.
Even Bigger Problem
Remember how I said that the FSE paper searched commits for defects? The commit message "add infix operators" has the string fix in it but isn’t about a defect. How did FSE filter it out?
They didn’t. TOPLAS manually reviewed 150 random defect commits. About one third of them were false alarms.
The review suggested a false-positive [false alarm] rate of 36%; i.e., 36% of the commits that the original study considered as bug-fixing were in fact not. The false-negative [missed defect] rate was 11%.
This is a critical threat to validity. It’s not an issue of noisy data or anything, something that could be waved off with better techniques. FSE simply didn’t understand the data. They mistakenly counted 200k safe commits as DFCs and 100k DFCs as safe. Regardless of any other issue, this alone is enough to ruin the paper.
Open Data
These are very significant flaws. Some of them are glaring. So why did it take four years for anybody to spot them? It’s not like this was an obscure paper. Surely someone would have seen the problems in the data.
Because nobody could see the data! The TOPLAS group had to explicitly ask FSE for the dataset, which was directly emailed to them. Unfortunately, this is the norm in academic research: people share papers but not datasets or scripts. In some cases there are legitimate reasons for this, like confidentiality or trade secrets. But for the most part it’s because sharing data is inconvenient or simply not considered. Scripts are even worse: not only do most people not consider them worth sharing, but often scientists are too embarrassed at the code quality to share them.
This is an increasingly serious problem for the field. Without being able to see the datasets, it’s almost impossible to vet a paper. And if you can’t see the code, it’s almost certainly flawed. “Science Code” is notoriously low quality. But we don’t know for sure unless we can see the source code. That’s why many high-profile journals are now requesting that people submit the code in addition to their paper. If the code is not provided, then the paper is wrong, end of discussion. The CACM does not require this.
That’s why the errors in the FSE data stayed hidden for so long. By contrast, all of the TOPLAS data and analysis is available here.
November 2019
By this point FSE and CACM combined had been cited over 200 times. This makes it a pretty influential paper as far as these things go. Now it’s been thoroughly debunked. Some of the problems are debatable- did TOPLAS use the right metrics? Are all of their critiques correct? But the “most commits are mislabeled” claim is an inarguable issue. Misclassifying the commits is much more fatal to the paper than which correction measure they used.
Such an insult can’t stand! It probably didn’t help that one of the TOPLAS authors, Jan Vitek, made fun of the FSE paper in a talk.
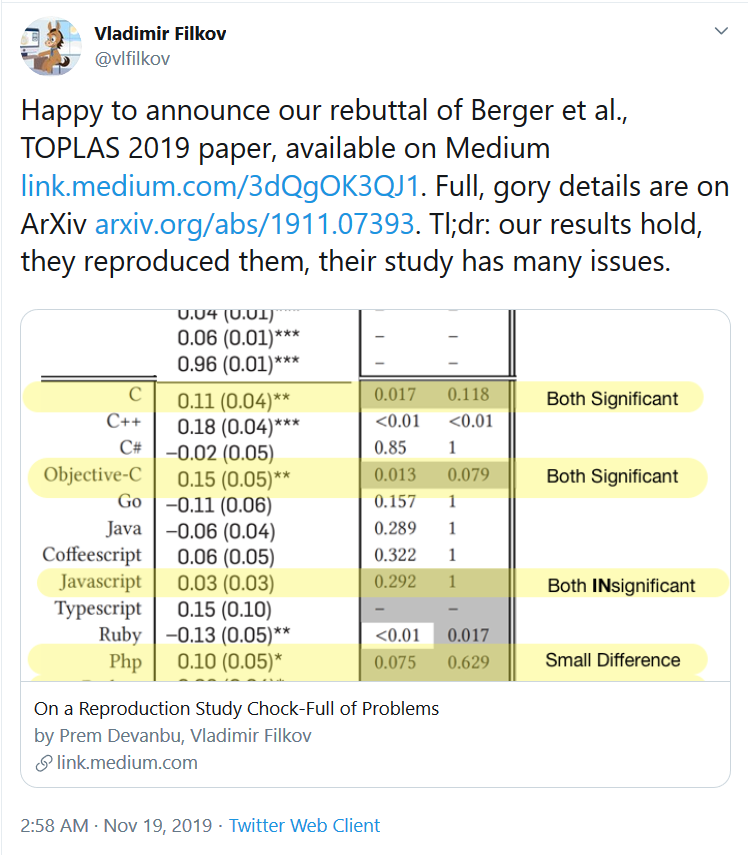
So the CACM folk published a rebuttal, Rebuttal to Berger et al., TOPLAS 2019, on the ArXiv.11 They also published a companion article on Medium, On a Reproduction Study Chock-Full of Problems. While they mostly cover the same material, they’re not identical, so we’ll collectively call them the “rebuttal”.
Most of the rebuttal is dedicated to arguments on statistical methods: Bonferroni vs FDR, zero-sum vs negative binomial, normalization methods. Three of the flaws are more interesting:
Old Data. First, the TOPLAS authors weren’t acting in good faith. Notice how in the last section I talked about the issues they found in FSE? They were looking at the 2014 FSE version, not the 2017 CACM paper. The latter is the definitive final version and has a bunch of cleanup the FSE paper does not have. So they’re looking at outdated data and deceptively telling people the modern version is wrong.
Berger et al. refer to results from both our preliminary, FSE paper and our final CACM paper in their TOPLAS paper comparisons, which creates confusion.
Same Outcomes. Second, while the TOPLAS claimed to see several problems with FSE, their reanalysis got the same magnitude of changes as the CACM paper. In other words, even after correcting all of the identified flaws, they saw the same effect from programming languages as CACM. In the rebuttal’s words:
As this is after all the additional TOPLAS19 data gathering, cleaning, and processing, this is to a remarkable degree a confirmatory study of our CACM19 [sic] RQ1
No False Alarms. According to FSE, the manual process for identifying defect commits isn’t actually much better than the automated process. When Devanbu and Filkov went over the list of buggy commits, they selected 12 commits at random and found that eleven of them were actually true positives.
When examining a subset (numbering 12) of the buggy commits which they claim are false positives, considering the commit logs, the actual changes, linked issue numbers (when available) and discussions (when available) we found that 1 was a false positive, but 10 were in fact true positives, with one other one being debatable. We are therefore skeptical of their claimed 36% FP rate of our method, and look forward to the development of a clarified, repeatable protocol which could lead to more reliable results.
I find these the most interesting because they’re “fundamentals” mistakes, not technical ones. Statistical analysis is a very difficult and niche skill that’s easy to get wrong. But these? These are failures in properly doing a replication. Replication is one of the core skills of science research! Think of it as the difference between “an off-by-one error in a bunch of pointer arithmetic” and “never running the test suite.”
It comes back to the integrity: do you trust these people to do their due diligence? If they’re using the old data, if they don’t understand their own conclusions, and especially if their biggest criticism is vacuous? Maybe not. The FSE folk made some major mistakes, but they corrected them for CACM. Perhaps the TOPLAS folk made bigger ones.
On Professional Courtesy
There two reasons to be skeptical of the rebuttal. The first is that the CACM people have a track record of making mistakes. We should also expect mistakes in their rebuttal, too. Second, if you’ve been following along, you might have noticed that the rebuttal has a very different tone from the two academic papers. The papers were precise and professional. The rebuttal, on the other hand, looks like this:

Scientific writing is often criticized as dry. And it probably too much is: even a little bit of style makes a paper much more pleasant to read. But we can also take it too far. Writing this charged is a sign that something is off.
This of course goes ways. Vitek’s talk was named “Getting Everything Wrong without Doing Anything Right”. It’s not clear if that contributed to FSE’s response, but I’d imagine so. Based on other actions I don’t think it was the sole factor, and it happened in an unofficial channel, while this response was the official one. Nonetheless, both sides contributed here. Part of the reason science favors emotionless writing is that it helps avoid feedback loops like this.
November 2019 (again)

Berger et al. publish FSE/CACM Rebuttal², which I will refer to as “the rebuttal rebuttal”. First, they noted that there are a number of claims in the replication that the rebuttal didn’t address. Things like not analyzing header files, or underestimating git developers, and LoC inconsistencies. They also addressed the three big points directly:
Old Data. As the replicators put it:
Nowhere in the email exchange with the FSE authors is there mention that we were given FSE data. We discovered it later, when we found numbers that did not match CACM.
Same Outcomes. They agree in degree of impact, but not in statistical significance. The replicators aren’t saying the effect is minimal, they are saying that the effect is statistically insignificant.
No False Alarms. First, they clarified their process: they had three developers review every sampled commit. Then they listed 70 commits that were obviously not defective. They did not, however, respond about the 12 mistakes FSE listed.
On Human Courtesy
How did FSE take the rebuttal rebuttal? Not well.
That’s a link to Berger’s Facebook account. Even if Berger did call him a donkey there, which he didn’t, that’s a really asshole thing to do!
This is where everything currently stands. It could be over now, and both sides think they’re right and move on with their lives. We might see a rebuttal rebuttal rebuttal.
But we’re not done just yet, because there are a couple of important loose ends.
Loose Ends
Is this even a good idea?
We’ve just spent several thousand words on methodology to show how the original FSE paper was flawed. But was that all really necessary? Most people point to a much bigger issue: the entire idea of measuring a language’s defect rate via GitHub commits just doesn’t make any sense. How the heck do you go from “these people have more DFCs” to “this language is more buggy”? I saw this complaint raised a lot, and if we just stop there I could have skipped rereading all the papers a dozen times over.
Jan Vitek emphasizes this in his talk: if they just said “the premise is nonsense”, nobody would have listened to them. It’s only by showing that the FSE authors messed up methodologically that TOPLAS could establish “sufficient cred” to attack the premise itself. The FSE authors put in a lot of effort into their paper. Responding to that all is “nuh-uh your premise is nonsense” is bad form, even if the premise is nonsense. Who is more trustworthy: the people who spent years getting their paper through peer review, or a random internet commenter who probably stopped at the abstract?
It all comes back to science as a social enterprise. We use markers of trust and integrity as heuristics on whether or not to devote time to understanding the claim itself. This is the same reason people are more likely to listen to a claim coming from a respected scientist than from a crackpot.12 Pointing out a potential threat to validity isn’t nearly as powerful as showing how that threat actually undermines the paper, and that’s what TOPLAS had to do to be taken seriously.
What about the false alarms?
There’s one loose end to the story: the spurious defects. The rebuttal selected 11 random “false defects” and showed they actually were defects. In response, the rebuttal rebuttal listed 79 commits that weren’t defects. But that’s not quite a response: it turns this into a “who do you believe more” kind of situation. Now I believe Berger et al. much more than Filkov et al., given their other responses and behavior, but I still don’t like this. At the very least it suggests that the replication was much sloppier in classifying errors than it claimed to be.
So I did some digging. The rebuttal helpfully lists the 11 commits that they looked at. Reading those commits, I had to agree with the rebuttal: they looked like actual defects, not false alarms. The next step was compare them with the replication datasets. They listed this GitHub repo of false alarms, and I confirmed that the “false alarms” were part of that list.
…Notice anything wrong with that page?
…
…
Scroll right.
I checked on an assortment of browsers and monitor-sizes and in all cases, the GitHub UX hides the third column. A 1 in that column means that the checked commit corresponded to an actual defect, a 0 means it was a false alarm. Of the 11 commits the rebuttal listed, 7 were marked with a 1. FSE said that TOPLAS shouldn’t be trusted because they incorrectly listed these as false alarms. In actuality, TOPLAS correctly listed them as actual defects, and FSE didn’t notice.
I find this damning. It’s the same kind of error that FSE made several times: some data looked good for them, so they didn’t investigate if it was actually good data. Seeing the best argument against TOPLAS fall apart so easily is the reason I trust the replication far more than the original paper.
Conclusion
It’s probably clear which “side” I’m on. The FSE scientists consistently made major mistakes in their process. There are also mistakes the TOPLAS folk made, too. But they weren’t to the degree of FSE, nor did TOPLAS act in such a strange way.
What are the takeaways here? Well, for one, how Not To Do Science. Be diligent with your threats to validity. Check all of your assumptions. Don’t blindly trust automation. Don’t dox other scientists. The usual.
But there’s also a deeper point here. We like to think of science as unbiased and purely rational. All we’re supposed to care about is the facts and the data. But that’s not the whole story. Signals like integrity, trustworthiness, and reputation matter. This is not a fatal flaw in science, more an acknowledgement that science is just like any other human process. Humans are messy and complicated. Science is our way of coping with that mess, not ignoring it entirely. It couldn’t work any other way.
Science has its problems, but it’s still the best we got.
I shared a first draft of this essay on my newsletter, all the way back in November. It’s pretty much the same content as my blog except weekly instead of monthly. So if you like my writing, why not subscribe?
Thanks to Dan Luu, Greg Wilson, and Felienne Hermans for feedback.
Update 2020-09-27
According to an Actual Statistician, I got my explanation of p-values wrong, see here.
Update 2021-05-16
Github as fixed their UX so now you can see all three columns of the CSV without scrolling.
- This is a log scale: we only see the commit factor dominate if we go from 16 to 48 commits, not if we go from 16 to 17. [return]
- Yes, that’s really high. Yes, something’s wrong. We’ll get to that in a bit. [return]
- He actually found several errors, but this was the biggest and most pertinent to this essay. [return]
- The essay originally said that the FSE article was a preprint. This was incorrect: the FSE paper was a full, peer-reviewed paper. Thanks to Stephen Kell for catching this. [return]
- This might make languages matter more. Some languages are terser than others, so languages that lead to smaller codebases would have fewer bugs. It’s not clear if they controlled for this specifically. [return]
- This is called the “natural log” for math reasons. The derivative of
ln(x)is1/x, and the derivative oflog10(x)is1/(ln(10)*x). [return] - Different fields see different citation numbers. This was the most popular paper of that conference. It might not seem like a lot to an ML researcher, where papers can easily reach thousands of citations within a year. [return]
- This is a common problem with any kind of corpus analysis. You have to make sure that all the samples you are analyzing are sufficiently different from each other and that you don’t have a hidden bias inside them. Corpus analysis is a very common technique in linguistics, and these failure modes are very well known. But there’s very little overlap between linguists and computer scientists, making it unsurprising that computer scientists aren’t savvy to this kind of error. [return]
- There’s a mistake in the paper here: before correcting for multiple hypothesis, they accidentally used a cutoff of
0.005, not0.05. This inadvertently causes more languages to lose significance in just the cleanup. But they applied MHC starting from a0.05cutoff, so the data is correct from there forward. [return] - ArXiv.org is a preprint host for math and physics papers. There’s also Psyarxiv.org for psychology papers and Vixra.org for crackpots. [return]
- About their field, I mean. Sometimes people roll their science cred into unwarranted claims about other fields. [return]