The Great Theorem Prover Showdown
Functional programming and immutability are hot right now. On one hand, this is pretty great as there’s lots of nice things about functional programming. On the other hand, people get a little overzealous and start claiming that imperative code is unnatural or that purity is always preferable to mutation.
I think that the appropriate paradigm is heavily dependent on context, but a lot of people speak in universals. I keep hearing that it’s easier to analyze pure functional code than mutable imperative code. But nobody gives rigorous arguments for this and nobody provides concrete examples. Nobody actually digs into why assignments and transitions are so much harder to reason about than pure functions and IO monads. We’re just supposed to accept it as an axiom.
I don’t like accepting things as axioms. If we make a claim, we better damn well put it to the test. So last Friday I did exactly that:
Here's the catch: I formally proved all three functions are correct. You have to do the same. And by "formally prove", I mean "if there are any bugs _it will not compile_". Informal arguments don't count. Quickcheck doesn't count. Partial proofs ("it typechecks") don't count.
— Inactive; Bluesky is @hillelwayne(dot)com (@hillelogram) April 20, 2018
Provable Correctness
What does “formal proof” look like? Let’s start with type checking. Here’s some pseudocode that returns the tail of the list.
fun Tail(input: list[A]) -> list[A]
begin
(input == []) ? [] : [input[0]] // wtf
end
What we mean here is that we only call it with lists and it will always output a list with the same type of elements as the input list. We can call well-typedness a specification about the program, where the type checker proves that specification is valid. Most languages make the type checker part of the compilation process, so it can only compile if we can prove that it always takes a list and returns a list. If it compiles, it’s well-typed, and we don’t need to test its well-typedness at runtime.
Of course, our Tail above is broken. That’s because the function’s type signature is only a partial specification of the behavior. While it’s great that Tail is well typed, there are plenty of other functions that have the same type signature but different behaviors. The full specification is this:
fun Tail(input: list[A]) -> list[A]
requires len(input) > 0
ensures output == input[1:]
begin
(input == []) ? [] : [input[0]] // now objectively wrong
end
If we had some way of statically checking the requires and ensures, we could prevent this from compiling. Then we could honestly say “if it compiles, it is correct.” The “statically checking”, of course, is the hard part. If you try to verify properties of programs you quickly hit walls like “the halting problem” and “computers hate you”. The process is labour-intensive and generally un-fun, but at least it’s objective. Either your program is proven correct, or it’s not.
That makes it perfect for a “reasoning about code” challenge. There’s no subjectivity here; every entry can be immediately and objectively judged based on whether it conforms to the specifications. If pure functions are always easier to analyze, then people would be able to quickly provide proofs for the three I did. This also isn’t an “unfair” challenge, in that only one field has active research in proofs. In general, there are *furious air quotes* “three” “main” “ways” people write these specifications:
- Dependent types: encode the specification into the type of the program. If it typechecks, it’s correct. Examples: Idris, Agda, F*.
- Contracts: encode the specification as assertions, pre/post conditions, and refinement types. Examples: SPARK, Liquid Haskell, Dafny.
- Theorems: write the specification as an independent mathematical theorem. Examples: Isabelle/HOL, ACL2.
There’s a bunch of overlap and stuff but dependent types are more often used in FP and academia while contracts are more often used in IP and industry. The important points, though, are that 1) formal proofs are a well-studied topic in both FP and IP, and 2) the paradigms tend to have different ways of doing proofs. So not only would we be able to compare the difficulty of the proofs, we would also be able to contrast how they’re done.
I chose to verify everything in Dafny, since it’s arguably the simplest and most lightweight IP verification language. It also has a free compiler online, so I could easily provide proof that the proofs are proofs. After learning the basics and shaving some yaks I did the first two problems in about an hour each and the last one in about three. That was my metric: if FP code was easier to prove than IP code, and a novice like me could do these problems in an afternoon, someone who’s already experienced with proofs should be roughly as fast I was.1
The Questions
- Leftpad. Takes a padding character, a string, and a total length, returns the string padded to that length with that character. If length is less than the length of the string, does nothing.
Leftpad is one of the simplest “interesting” things to prove. Anybody can understand the concept and code a working version. But it’s quirky enough that specifying it is a good exercise. You have to specify it’s the right length, that the added characters are all the padding character, and that the suffix is the original string. Then you have to actually prove all of these properties. Not bad for a one line function!
This was all a happy accident, though. My reason for making Leftpad the first was that I already saw a version proved in Liquid Haskell. I thought that would make the first problem a gimme. If someone couldn’t prove it, they could just link to the LH version and move on to Unique. In practice, though, Leftpad proved a lot harder than Unique, and the freebie version was invalid, as we’ll discuss later.
- Unique. Takes a sequence of integers, returns the unique elements of that list. There is no requirement on the ordering of the returned values.
Not a hard one. All we’re asking here is that you can convert a list into a set and back again. I included it because it was the first thing that I proved in Dafny, and because I (wrongly) thought it would be mildly harder than Leftpad. In retrospect, I really should have swapped the order of the first two.
One interesting thing about unique is that it’s “unstably” easy, in that it only works because it’s symmetric to a set. Any tweak that breaks that symmetry makes the problem a lot harder. For example, if you had to return the unique elements that had duplicates, you’d have to encode global properties of the list. As we’ll discuss with Fulcrum, that gives an advantage to imperative proofs. But that wasn’t part of the challenge.
I also realize, as I write this, that I only proved it one-way. I specified that all elements of the original list are in the output, but not that all elements of the output were in the original list. If the method took in [1, 2, 2] and returned [1, 2, 99], it would still pass the partial specification. I really dropped the ball on this one.
- Fulcrum. Given a sequence of integers, returns the index i that minimizes |sum(seq[..i]) - sum(seq[i..])|. Does this in O(n) time and O(n) memory.
This was the main challenge. If you implement it inefficiently it’s not too bad: just calculate the value for every index and then take the min. If you want to do it efficiently, though, the problem turns really nasty. The best way to do that is to partially compute the result, prove some theorems about the intermediate values, and then use that to compute the final index. In my experience intermediate proofs are easier when you have loop invariants and mutation than when you have to use accumulators and recursion. So unlike the other two, Fulcrum was intentionally chosen to be harder to prove functionally.
As Michael Arntzenius pointed out, the commented examples in that code are wrong. I specified the index i to be the sum of the first i elements compared to the remaining |seq|-i elements, but mentally flipped it when adding the comments. I’m normally pretty skeptical of the “trust the code, not the comments” mantra, so screwing up the comments was an ugly lesson for me.
The Results
Everybody got stuck on Leftpad.
Okay not really. But there was an immediate burst of people saying “this will be easy” followed by the same people saying “wait, this is actually pretty hard.” Turns out formal analysis is a tough problem! A lot of people tried to argue the challenge was missing the point and that purity was always better even if they couldn’t formally prove the pure functions. Then some formal methods folk got the first two challenges finished and started working on the third.
Then Vitalik Buterin retweeted me, a whole host of naysayers jumped on board, and Twitter locked my account. Twice.
Can’t please everyone.
Leftpad
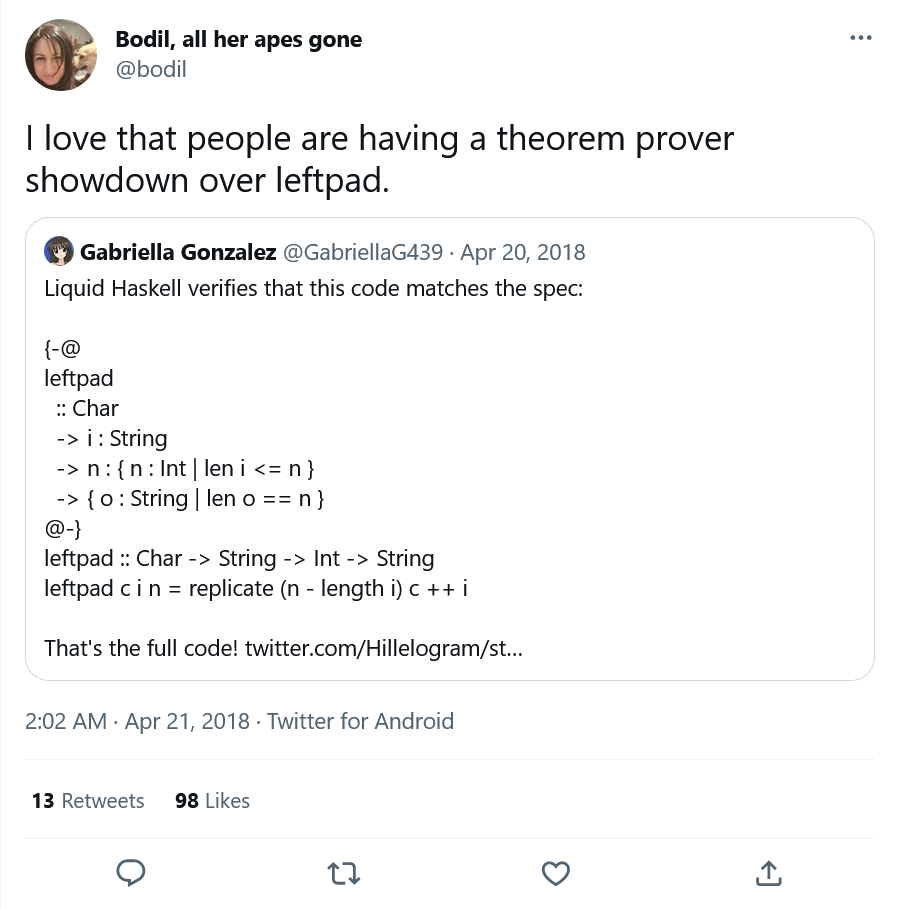
As I mentioned before, Leftpad was supposed to be a gimme. Someone could just link the verified version that inspired this and we’d all move on. But once somebody did, I found out it was flawed: the writer used assume to declare intermediate steps were true by fiat. In Dafny, that would verify but not compile, forcing you to prove your assumptions before running the code. In Liquid Haskell, that would verify and compile, letting you run unproved code.2 That didn’t match the requirements and I disqualified it.
The first attempts at this were all partial proofs, usually leaving out “the output has the fill as a prefix”. A couple solutions were claimed to be “obviously true”, which has issues we’ll cover later. Stephen Checkoway did the first correct proof in Dafny, using recursive functions instead of loops. Right after that the challenge hit theorem-prover Twitter and everybody started sending in solutions. We now have verified Leftpad in Liquid Haskell, Agda, Coq, F*, Isabelle, and Idris.3
I also got a bunch of imperative solutions verified in other languages, like SPARK, ATS, and Whiley. If the only result of this challenge is that Leftpad becomes the theorem prover’s “hello world”, I’ll be pretty happy.
Unique
Not a whole lot of people were interested in this one, which makes sense. It’s got neither the meme appeal of Leftpad or the raw challenge of Fulcrum. Most of the proofs submitted here either didn’t return a list or didn’t prove that all elements of the input were in the output. As I said above, my version wasn’t a whole lot better, as I didn’t prove the two-wayness of the elements. Solutions that matched at least my partial spec, though, were done in Agda, Liquid Haskell, pure Dafny, Idris, and Coq.
Fulcrum
Two days after I posted the challenge, David Turner got in the first working version of a pure Fulcrum.
Fulcrum was way harder than expected. I stayed tail-recursive which I don't think helped. Also the standard library was less useful: e.g
— ∃! David Turner (@DaveCTurner) April 22, 2018
. no way to find the minimum index.
Likely that it can be cleaned up with some refactoring, but here's my first go.https://t.co/16xbndYcWv
In addition to Turner (who used Isabelle), Arntzenius did a brute force solution in Agda, Checkoway used Pure Dafny, and Ranjit Jhala wrote a solution in Liquid Haskell. I think everybody found this much harder than they expected, which is what I was hoping for.
The Crowd
The Theorem Provers
Every single one of the people who sent a proof was, with no exception, incredibly civil, friendly, and engaging. Most of the provers didn’t have strong opinions on FP versus IP: they were more interested in trying the challenges than making a point. Many people here were writing proofs for the first time, or using new languages for the first time, or just were showing off their favorite tools. I’ve gotten Leftpads in ancient systems, in domain-specific provers, and in type systems so experimental they’re not even public yet. One person is currently trying to prove it with mypy. I’m like 90% sure this is impossible but really hope it isn’t.
The Theorem Prover-Provers
Turns out theorem provers are written by people, and many of these people have twitter accounts. A bunch of them pitched in with both solutions and their thoughts on formal verification. There were a lot of really good tangents here, and I’m definitely missing some, but I tried to compile the highlights.
- James Wilcox, one of the contributors to Dafny, shared his thoughts on what made imperative “harder” than FP. His thoughts: the heap. A bunch of other TPPs immediately went “oh yeah, that makes perfect sense.”4
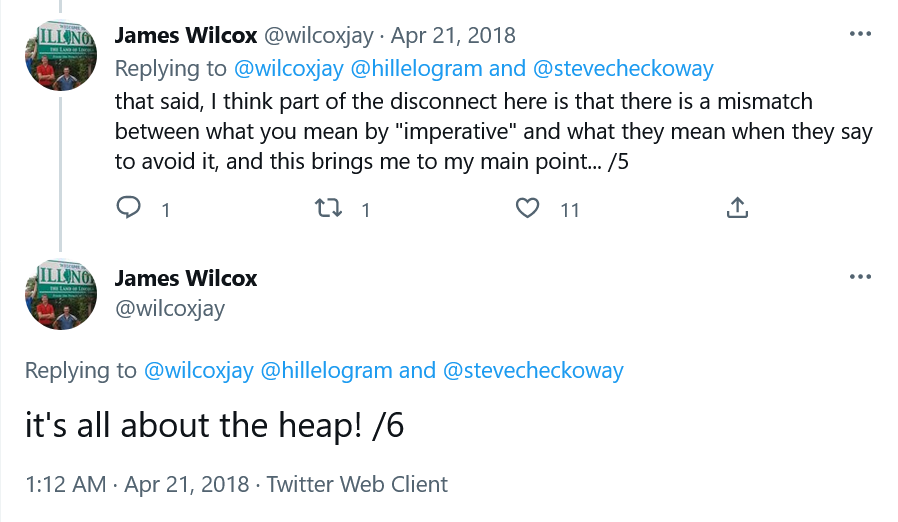
- Ranjit Jhala, who develops Liquid Haskell, did the first two problems in LH and talked about the differences in how functional and imperative code “use the heap”.
Thanks @wilcoxjay for putting so nicely what I meant by the dfy examples are mostly FP! The crux is indeed the heap. (1/3) https://t.co/b9tGDKehD9
— Ranjit Jhala (@RanjitJhala) April 21, 2018
- Edwin Brady and Jan de Muijnik talking about what lessons from other proof systems they’re thinking of adding to Idris:
We can even look to integrate with constraint solvers and see how they can helps us.
— Jan de Muijnck-Hughes (@jfdm) April 22, 2018
Off Twitter, David Pearce wrote about some possible issues Leftpad exposed in his theorem prover and Neel Krishnaswami emailed me his thoughts on the interplay between procedures, aliasing, state, and formal verification. He’s going to be writing a fuller post which I’m really looking forward to reading you can now read here!
The Thought Leaders
A lot of people didn’t write proofs but still put in great insights. Some of my favorites were:
Yaron Minsky talked about modularity in different programming paradigms.
Cesar asked “why not a verified APL?”
Greydon Hoare and Ron Pressler got into a debate on the economics of formal verification.
Justin Le had some thoughts on how different program communities have different verification cultures.
And Lindsey Kuper summarized about half the fundamental problems with formal verification in a single tweet:
I don't have a dog in this functional/imperative fight, but I feel like there's some stuff missing from this conversation about what correctness means (wrt what spec?), what the underlying assumptions are about how code is executed, and about the TCB in each case.
— Lindsey (@lindsey) April 21, 2018
The Bulldogs
A common critique of FP communities is they have very aggressive people and this held true here. Several people jumped in to tell me that imperative languages were worthless and I was an idiot for making this challenge. None of these people actually provided any solutions, and when I pressed them on this they all said it was so trivial in FP that doing was a waste of time.
I was expecting some blowback like this, but what really surprised me was how there was zero overlap between the provers and the bulldogs. I was expecting at least some overlap: somebody who mocked me but also provided a valid solution, or even tried but failed. But that didn’t happen.
I normally assume these people are “brilliant jerks”: they’re assholes online, but I still have to listen to them in case they say something important. This really cracked that assumption: none of the “brilliant jerks” were willing to put any skin in the game.5 You don’t have to listen if they have nothing to say.
The Naysayers
A bunch of people chimed in to say that the argument was stupid: not because it was so easy to prove these in FP, but that it didn’t matter. According to them, “FP is easier to reason about” is true even though they couldn’t prove the FP programs correct. Here are my responses to the most common arguments.6
“You don’t need to prove FP code because it’s obviously correct.”
There are three problems with this argument. First of all, this confuses high-level and low-level primitives. My functions were intentionally low-level, not relying on any standard library to get stuff done. Saying that FP code is more “obviously” correct is just saying that you used higher-level primitives than I did, not that IP doesn’t have those kinds of operations available. As one person points out, the APL solution to Fulcrum is one line. Does that mean that array languages are more obviously correct than functional ones?7
Second, when you use high-level primitives, you’re relying on them being correct. This isn’t always a safe assumption. If you write sorted = sort(list), are you guaranteed to get a sorted list? Not if sort overflows.
Finally, most people who said this also provided obviously correct solutions… almost all of which were wrong. People missed edge cases or didn’t implement the full specification.
“Even if I can’t prove small programs correct, FP is better for proving big programs correct.”
Everybody gave abstract arguments for why this would be true, but they all had to explain why the logic didn’t apply to my examples. I consider concrete examples better evidence than abstract arguments. Sure, there are cases where small-X is false but big-X is true, but when people claim big-X is true despite small-X being false, and are unable to bring up concrete evidence, we should be pretty skeptical.
Not to mention that, if we’re talking about big programs, the most robust “big programs” are all written in Ada or DO178C-compliant C. Does that make C the best language for reasoning about code? I’d personally put much more faith in the Cleanroom process than any language when it comes to correctness.
“Being easier to reason about doesn’t mean reasoning about correctness, it means reasoning about integration/composition/refactoring/architecture.”
This is moving the goalposts. Many of the people claiming this were equally happy, in other discussions, equating “analysis” with “correctness”. I chose correctness because it was the easiest to objectively verify. I’m sure that if I posed a similar challenge about refactoring code, everybody would be telling me that “being easier to reason” isn’t about refactoring, it’s clearly about correctness!
“IP is still wrong because of Curry-Howard Correspondence.”
I don’t even know what to say about this one.
Final Thoughts
There’s two main takeaways for me.
The first is what I set out to show: the claim “it’s easier to reason about FP than imperative” is wrong. At best you can say “there are many more problems where it’s easier to reason with FP than imperative”, which I still think is probably wrong but at least isn’t definitely wrong. I believe almost all of the proof writers are on board with this. I also believe some of them are still mad at me about Fulcrum. Regardless, which paradigm is “easier” to reason about heavily depends on your problem domain and algorithms you’re writing.
The second is that the formal verification community is pretty great. I now have over a dozen Leftpad versions and more are on their way. I’m planning on collecting them all along with explanations, so interested people can compare the different implementations. Even in the same paradigm you get pretty big differences in style. The Agda and Idris proofs look nothing like each other, despite both being encoded in dependent types.
This was also my first introduction to proving code correct, even though I do formal methods! It’s a diverse field and my niche, formal specification, is very different from this kind of work. So it was pretty nice to explore another part of the field for a while. Shameless plug: I’m writing a book about formal specification in TLA+, which should be out… Julyish? Assuming I’m not struck by lightning. There’s no official preorder, but if you’re interested, just email me and I’ll let you know when it’s done.
Update 4 / 26
A couple of common criticisms I want to address:
With parametric types you’d get the missing Unique spec for free.
This is true and a good argument in favor of using parameterized static types as part of your spec. And I’m not saying that FP analytic techniques are bad! A lot of them are really good for program analysis. My problem is that we take this to an extreme, often disregarding IP analytic techniques as worth using. In reality, we should be considered both.
And note that, in this specific case, parametric types aren’t an FP-only thing. My Dafny Unique uses ints, but that’s because of my relative weakness with Dafny than a limitation of the language. I could rewrite the spec to use set<T(==)> and also get the theorem for “free”. However, Dafny is unable to prove it automatically, while Liquid Haskell can.
The imperative loops can be trivially translated into recursive functions.
While this is true, it’s not true that the loop invariants can be trivially translated into recursive function proofs! You have to redo your specifications and your proofs. That’s what people struggled with.
Sometimes proving loop invariants is easier than proving recursive specs. Sometimes it’s the other way. In formal verification we can exploit this: sometimes the best way to prove B is correct is to find some f where f(A) = B and then prove both f and A are correct.
Update 8 / 6
You can now read explanations of all of the Leftpad proofs here.
- While I’ve never written programmatic proofs before, I’ve got a math degree and write TLA+ for a living. Comparing my pace with a complete novice unfairly stacks the deck for IP, as opposed to me choosing the problems, which fairly stacks the deck. [return]
- This is not a knock on Liquid Haskell, which is a great verification platform. As one of the devs shared, Haskell has a huge standard library and they haven’t fully specified it, so letting you run assumptions by default makes LH more useful at the cost of more developer responsibility. But that doesn’t match the params of this challenge. [return]
- If you only click one link, make it that one. C’s proof is incredible. Here, I’ll link it again so you can open it in a new tab right now. [return]
- He also showed that my original version of Fulcrum was actually O(n^2), which I had to fix. :( [return]
- I mean, maybe they really can prove them but just don’t feel like it right now. And maybe my uncle really does work at Nintendo and lets me play games on the Playstation 6 [return]
- I make no guarantee that I’m representing their arguments faithfully. I have an agenda, after all. Feel free to dig through the threads to get the full context. [return]
- On second thought, I am 100% okay with this. If you want to write correct code, you gotta use an APL. This is the hill I want to die on. [return]