Probabilistic Modeling with PRISM
In my job I dig up a lot of obscure techniques. Some of them are broadly useful: formal specification, design-by-contract, etc. These I specialize in. Some of them are useful, but for a smaller group of programmers. That’s stuff like metamorphic testing, theorem proving, constraint solving. These I write articles about.
Then there’s the stuff where I have no idea how to make it useful. Either they’re so incredibly specialist or they could be useful if it weren’t for some deep problems. They’re interesting, and I want to write about them, but it can take months before I come up with any good motivating examples.
PRISM is one of them. The idea makes a lot of sense. TLA+ and Alloy are good for absolutes. You can say “there exists an error in this design”. But you can’t express statistical properties, like “this should take an average of less than 10 minutes” or “it is more likely this recovers than crashes.” Nor can you assign weights to actions, like “this has an 80% chance of continuing and a 20% chance of failing.” For that, we need probabilistic modeling (PM). PRISM is one such modeling language, and comes with some really powerful tools to inspect probabilities. But there’s a fundamental tradeoff in modeling: the more powerful the checker, the less expressive the language. And to get such a powerful checker, PRISM has to make some serious expressivity tradeoffs.
Let’s play with an example!
The Example
Two people are playing a game. The game is broken into a series of matches- you win if you win N matches. Player one is significantly better than the other and wins a match with probability K. K is fixed and does not change between matches. So it could be “first to 2 wins”, and p1 wins 60% of the time, or “first to 7 wins” and 90%.
They’re also playing casually, not competitively. To make it more balanced, p2 gets a handicap: they already start with H points. For a given N and K, the players want to pick H so that they’re as evenly matched as possible- each has roughly a 50% chance of winning the series.
The Model
Let’s start with the model first:
Show Model
dtmc
const int N; // Max wins
const double K; // p1 win rate, should be >= 1/2
formula still_playing = (p1 < N) & (p2 < N);
module game
p1 : [0..N] init 0;
p2 : [0..N] init 0;
[] (still_playing) ->
K: (p1' = p1 + 1)
+ (1-K): (p2' = p2 + 1);
[] !(still_playing) -> true;
endmodule
Now for the breakdown:
dtmc
We start with a tag saying what type of model it is. dtmc means it is fully deterministic with discrete time: the simplest probabilistic model. PRISM can also handle continuous-time models, realtime, and nondeterministic models.1
const int N;
const double K;
N is the number of matches needed to win the series, K is the probability at which P1 wins. K is between 0 and 1. Since these constants aren’t specified, we can choose them per simulation.
formula still_playing = (p1 < N) & (p2 < N);
We say we’re still playing if neither player has won N times yet. We have to put the formula outside of the module Because Of Reasons.
module game
p1 : [0..N] init 0;
p2 : [0..N] init 0;
Modules store our actual logic. They also define local variables. p1 and p2 are integers restricted to the range 0 to N.
Next comes our first command:
[] (still_playing) ->
The start of the command is an action (blank here) and a guard (still_playing). The command can only happen if the guard is true. It’s possible for a model to have multiple valid guards at once, in which case any one of them can happen.2
K: (p1' = p1 + 1)
This is one of the updates of the command. It happens with probability K. All it does is increment p1 by one. An update can change multiple different variables at once.
+ (1-K): (p2' = p2 + 1);
The + indicates it’s part of the same command. This update happens with probability (1-K): the set of all updates in a command must add up to probability 1. It increments p2.
In summary: this command can happen if we’re still playing. It says there’s a K chance of incrementing p1 and a (1-K) chance of incrementing p2.
[] !(still_playing) -> true;
endmodule
Setting the update as true means that nothing happens. It’s just here to prevent deadlocks. We could also use this to represent ties, adding a true update to our still_playing command.
Now we have a model, we want to ask what properties it has.
A Tangent on PRISM’s Property Model
PRISM expresses properties as an expanded version of Linear Temporal Logic, or LTL. It takes the basic building blocks and adds the power to describe properties. LTL by itself is pretty rich, PRISM’s extensions even moreso. Let’s go through some examples:
P=?[p1 = 1]
That represents the probability that p1 = 1 in the first step. That’s going to be 0, as p1 already starts at 0. If we instead write
P=?[X p1 = 1]
X means “the next state”, so this the probability that p1 wins the first match. X X p1 = 2 would be the probability that p1 wins the first two matches.
P=?[F p1 = 1]
F means “finally”, or “eventually”. This is the chance that
p1 has, at some point during the series, won exactly one match. We can combine F with X.
P=?[G p1 < 2]
G is “global”, or “henceforth.” This is the chance that p1 is 0 or 1 for the entire duration of the series.
There’s a few other temporal operators, but those are the main ones we care about. We can also combine operators. If we do
P=?[F G p1 = 1]
“Eventually henceforth p1 = 1.” It’s the probability that p1 reaches 1 but does not go past it.
To get the win rate, we’d want something like F G p1 = N. But we have a shortcut. Our model is guaranteed to always terminate, or reach a steady-state. Instead of P, we can use S, which gets the probability of us reaching a particular steady-state:
S=?[p1 = N]
Once we have a property, we can validate the probability with respect to some constants. I’ll write a validation like this:
S=?[p1 = N]
N=1, K=.6 //constants
-> 0.6 //probability
N=2, K=.6
-> 0.648
As a sanity check, let’s also test S=?[p2 = N], which should be the inverse probability.
S=?[p2 = N]
N=1, K=.6
-> 0.4
N=2, K=.6
-> 0.352
Alright so far. We can also add labels to clean up our properties:
label "p1_wins" = p1=N;
label "p2_wins" = p2=N;
S=?["p1_wins"]
N=1, K=.6 -> 0.6
Experiments
What would happen if I increased N? We’d expect that p1 would start winning more series. But it’d be tiring to manually validate all of the values of N. Instead, we want to do an experiment. In PRISM, experiments will create a table for a property over a given interval. I can take two properties:
S=?["p1_wins"]
S=?["p2_wins"]
If I fix K=0.6 and tell PRISM to run an experiment over N = 1-5 in increments of 1, then it outputs a graph:
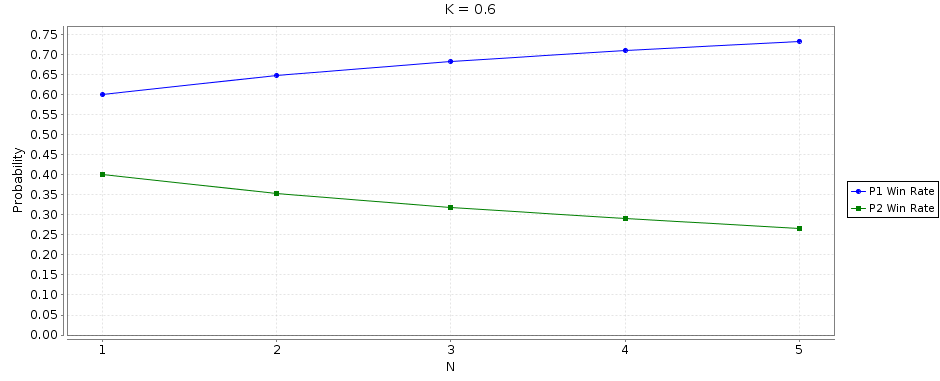
Show Table
| N | p1_wins |
p2_wins |
|---|---|---|
| 1 | 0.600 | 0.400 |
| 2 | 0.648 | 0.312 |
| 3 | 0.683 | 0.317 |
| 4 | 0.710 | 0.290 |
| 5 | 0.733 | 0.267 |
Handicaps
I really like PRISM’s “queriability”. You can express some pretty complex properties. If p2 gets a point, what’s the probability that they go on to win?
P=?[(F p2 = 1) & (F "p2_wins")] / P=?[F p2 = 1]
N=3, K=0.6 -> 40.4
It makes sense that p2 is more likely to win if they get at least one point. The only cases where they don’t get at least one point is if the game is a shutout in p1’s favor. Our restriction would then only remove games where p1 wins, so would raise p2’s chances.
Similarly, p2 would be even more likely to win if we gave them a 1-point handicap. Having a handicap is equivalent to always winning the first match. In contrast, F p2 = 1 covers any match which isn’t a shutout. p2 is much more likely to win from a score of 0-1 than a score of 2-1.
"point_bonus": P=?[(X p2 = 1) & (F "p2_wins")] / P=?[X p2 = 1]
N=3, K=2 -> 0.53
That’s actually pretty close to a balanced match! But I don’t like it when things are too easy for me. Let’s instead say that p1 wins 70% of the time and has to win 5 matches. Under these rules, p2 wins just 9.9% of the time. A one-point handicap boosts them up to 19%, which is still not balanced.
We can’t just extend our “point_bonus” property, as X just means the next state. For a handicap of 2 we’d need to write X X, for 3 X X X… that’s not general enough. There are a few things we can do instead, but the easiest is to just modify the spec itself. We can add an extra constant that corresponds to how many points p2 starts with:
+ const int H; // Handicap
formula still_playing = (p1 < N) & (p2 < N);
- p2 : [0..N] init 0;
+ p2 : [0..N] init H;
S=?["p2_wins"]
N=5, K=0.7, H=0 //No handicap
-> 0.098
N=5, K=0.7, H=1 //One point handicap
-> 0.194
In fact, we can use the experiment feature to output a nice table for us:
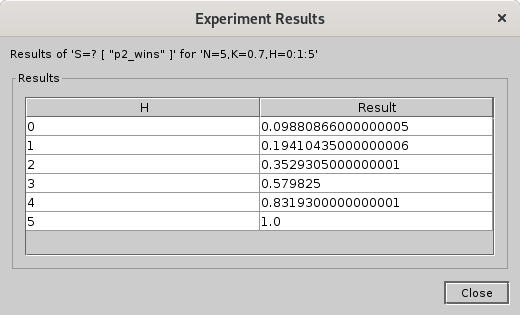
Show Table
| H | Result |
|---|---|
| 0 | 0.099 |
| 1 | 0.194 |
| 2 | 0.353 |
| 3 | 0.580 |
| 4 | 0.832 |
| 5 | 1.000 |
Under these conditions, the closest we can get to “balanced” is a 3-point handicap. This is less balanced than we could get with 3 matches at a 1 point handicap, but nonetheless is the best we can do under the given constraints.
Limitations
PRISM seems like a pretty powerful tool! I might have been a bit too hard on it earlier. Why not extend the model? Maybe we want to model a four player game. Instead of one K value and hardcoded p1 and p2, we’d need to use win_probability and matches_won tuples.
There’s just one problem: PRISM doesn’t have tuples. It also doesn’t have arrays or sets or maps or even strings. There’s only three types of value: integers, doubles, booleans. That’s it. If you want four players you have to hardcode four of each variable.
The lack of strings is worse than you’d think. Without strings you’re back to storing distinct states as numbers, meaning you see a lot of specs like this:
// 1: off
// 2: booting
// 3: on
// 4: error
state: [1..4];
Let’s try a different idea. Some video games have an inbuilt catchup mechanic: if one person is falling too far behind they might be given a small bonus to help close to the gap.3 If we want to model this, we’d need a convenient way to get how far each person is from winning. Something like:
formula matches_left(player) = N - player
But we can’t do this, because formulas can’t take parameters. There’s no way to write function that takes a parameter. You have to hardcode everything.
There are also severe ergonomic limitations but those are the two biggest fundamental limitations. As far as I can tell, this is a conceptual tradeoff: part of the reason PRISM is able to even check complex probabilities is because the spec language is so limited. They have to guarantee that everything is bounded and it’d be easy to break that with arrays.
That’s also why I don’t think it’s that useful. It took me months to find a good example because everything I could think of either required strings, tuples, or functions. There are lots of interesting problems that you might want to solve, but very, very few of them are cleanly expressible in PRISM.
Conclusion
I don’t dislike PRISM. It’s fun to play with and I like being able to answer dumb probability questions. It’s just… what do you even do with it? I know they’ve published some case studies, but I don’t know of anyone using it in industry, and I’ve met DRAKON programmers.
Is it worth learning? I don’t think so. It’s not going to be useful unless you’re absolutely sure you don’t need tuples. It’s definitely interesting, for sure, but so are a lot of things. I’d have had as much fun learning Z3 or Racket or SPARQL or compilers, and those would have been much more useful. But that’s part of the deal with exploring: not everything you find is gonna shake the world.
Also, my opinions are based on the tool, not the idea. If they added bounded tuples, strings, and simple functions, then suddenly this would be a lot more useful. And it might be that I Just Don’t Get It. If you’ve used PRISM or a similar tool in production, please shoot me an email! I’d love to hear your story.
Thanks to Jay Parlar for feedback.