Modeling Zero-Downtime Deployments with TLA+
I’m working on some examples for my TLA+ guide and realized this one would be a good introduction to specification in general, so I simplified it a little to make it more accessible. Enjoy!
The problem
Deploying code to a set of servers is tricky. You can turn them off, migrate the code, and turn them back on, but that’ll piss off the customers. You could also update them live, but different servers update are different rates and customers could get inconsistent results. So we’ll call a zero-downtime deploy one where
- There is always at least one server accessible to the client.
- All servers accessible to the client are running the same code.
Then there are all sorts of complications: do you need a minimum number of servers active? Can a deployment fail? Are there different types of servers running different codebases? What if you have to hotfix the code and redeploy, but the first deployment is still ongoing?
As with any complicated system, it makes sense for us to design it up from, and then check the design itself for bugs. We’ll be using TLA+ for this, part because it’s especially good at specifying concurrent systems and part because I like it and like shilling it. So let’s model a zero-downtime deployment!
We start with some setup and imports:
---- MODULE deployments ----
EXTENDS TLC, Integers
(* --algorithm deploy
\* everthing else happens here
end algorithm *)
====
Don’t worry about the boilerplate, it’s necessary but doesn’t affect what we’re writing. Next, some variables to model:
variables
servers = {"s1", "s2", "s3"}
servers is a set. So, three possible servers, each represented by a string.1
updated = [s \in servers |-> FALSE]
updated is a function. This might be a little unintuitive, but TLA+ functions are really more similar to dictionaries or hashes than programming functions or methods. If we were in Python, it’d be as if we wrote {"s1": False, "s2": False, "s3": False}. Unsurprisingly, this means that none of our servers are updated to the new code.
Now we have enough to define our first constraint:
define
SameVersion ==
\A x, y \in servers:
updated[x] = updated[y]
end define
SameVersion is an operator, which is the TLA+ ‘equivalent’ of programming functions. It says if you take any two arbitrary servers, they must have the same updated value. So either all servers are updated or none of them are updated.2
Now for the actual logic:
fair process update_server \in servers
begin Update:
updated[self] := TRUE;
end process;
By writing update_server \in servers, we create a separate update process for each server. The process itself will start out fairly simple: just set the appropriate flag to TRUE.
Here’s the final code:
EXTENDS TLC, Integers
(* --algorithm deploy
variables
servers = {"s1", "s2", "s3"},
updated = [s \in servers |-> FALSE];
define
SameVersion ==
\A x, y \in servers:
updated[x] = updated[y]
end define
fair process update_server \in servers
begin Update:
updated[self] := TRUE;
end process;
end algorithm; *)
We’re done! Except that deployment model is horribly broken. We aren’t actually doing anything to check that the servers are consistent. Before we do that, let’s see how TLA+ can find how it’s horribly broken without our help.
Checking the Model
We compile the TLA+,3 create a ‘model’, and then specify SameVersion as an invariant. That means that SameVersion has to hold true after every possible step in every possible behavior.
Lets dig into what we mean by that a little more. A server updates in a single step. There are three servers. So that’s three steps to check, right? Well, not exactly. We didn’t put any restrictions on what order the servers can update. So the order can be s1, s2, s3 or s3, s2, s1 or s1, s3, s2, etc. There six possible orderings, or behaviors, each with three steps. So SameVersion has to hold true for all 18 steps. If we added a fourth server, we’d then be checking up to 4!*4 possible steps. And we haven’t even made this complicated yet!
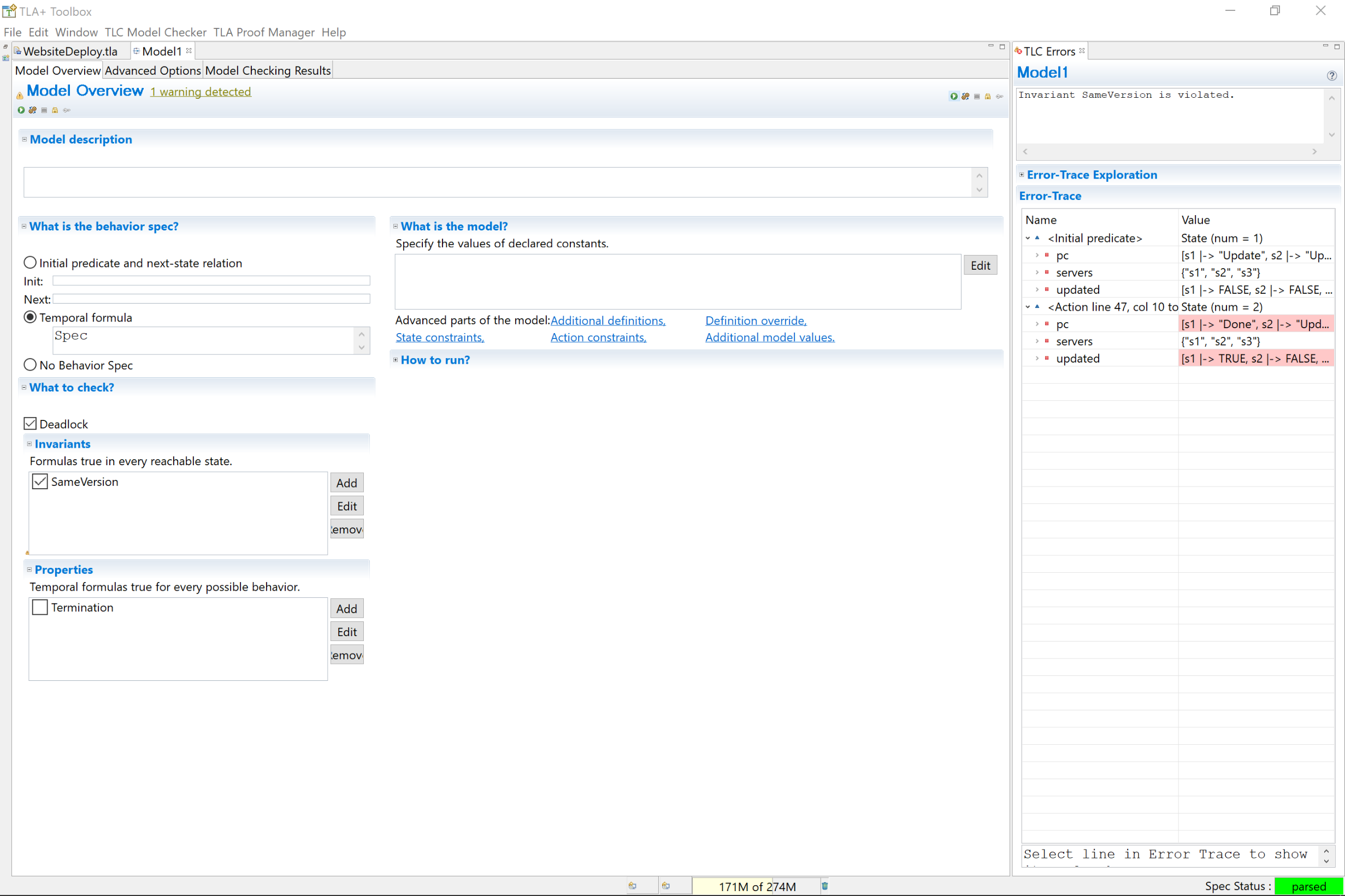
As it turns out, we don’t need to look very far for an error. All we need to do is update s1. Then updated[s1] = TRUE, updated[s2] = FALSE, and SameVersion is broken. Let’s fix it.
Fixing it
One thing we could do is assume the servers are in a load balancer, pull all but one out, and then update everything. We’d need a load balancer and some sort of flag to keep the servers from only updating when everything’s properly set up. Let’s add another process that coordinates the deployment to make everything easier.
variables
servers = {"s1", "s2", "s3"},
+ load_balancer = servers,
+ update_flag = [s \in servers |-> FALSE],
updated = [s \in servers |-> FALSE];
define
SameVersion ==
- \A x, y \in servers:
+ \A x, y \in load_balancer:
updated[x] = updated[y]
end define
fair process update_server \in servers
begin
Update:
+ await update_flag[self];
updated[self] := TRUE;
end process;
+fair process start_update = "start_update"
+ begin
+ StartUpdate:
+ load_balancer := {"s1"};
+ update_flag := [s \in servers |-> TRUE];
+ end process;
Most of this isn’t too different from where we started, except that we use start_update pull everything but s1 out of the load balancer before setting the update_flag for all of the servers. Since they each have an await statement, they can only run after start_update sets the flags, at which point there’s only one server in the load balancer. If we compile and run this, everything works!
Until we remember that we were asked to model a zero downtime system and we aren’t specifying any “downtime”. So let’s add that. In addition to TRUE and FALSE, we’ll add a third state called UPDATING4 and require that there is at least one server in the load balancer that’s not updating. Additionally, we’ll require that a server has to spend one step updating before it’s ready.
+ CONSTANT UPDATING
\* boilerplate
define
+ ZeroDowntime ==
+ \E server \in load_balancer:
+ updated[server] /= UPDATING
SameVersion ==
\A x, y \in servers:
updated[x] = updated[y]
end define
\*
fair process update_server \in servers
begin
Update:
await update_flag[self];
+ updated[self] := UPDATING;
+ FinishUpdate:
updated[self] := TRUE;
end process;
Each update_server now takes two steps. Instead of 6 behaviors and 18 steps, we have up to 90 behaviors and 1170 steps.5 Are there any of them broken? Yup!
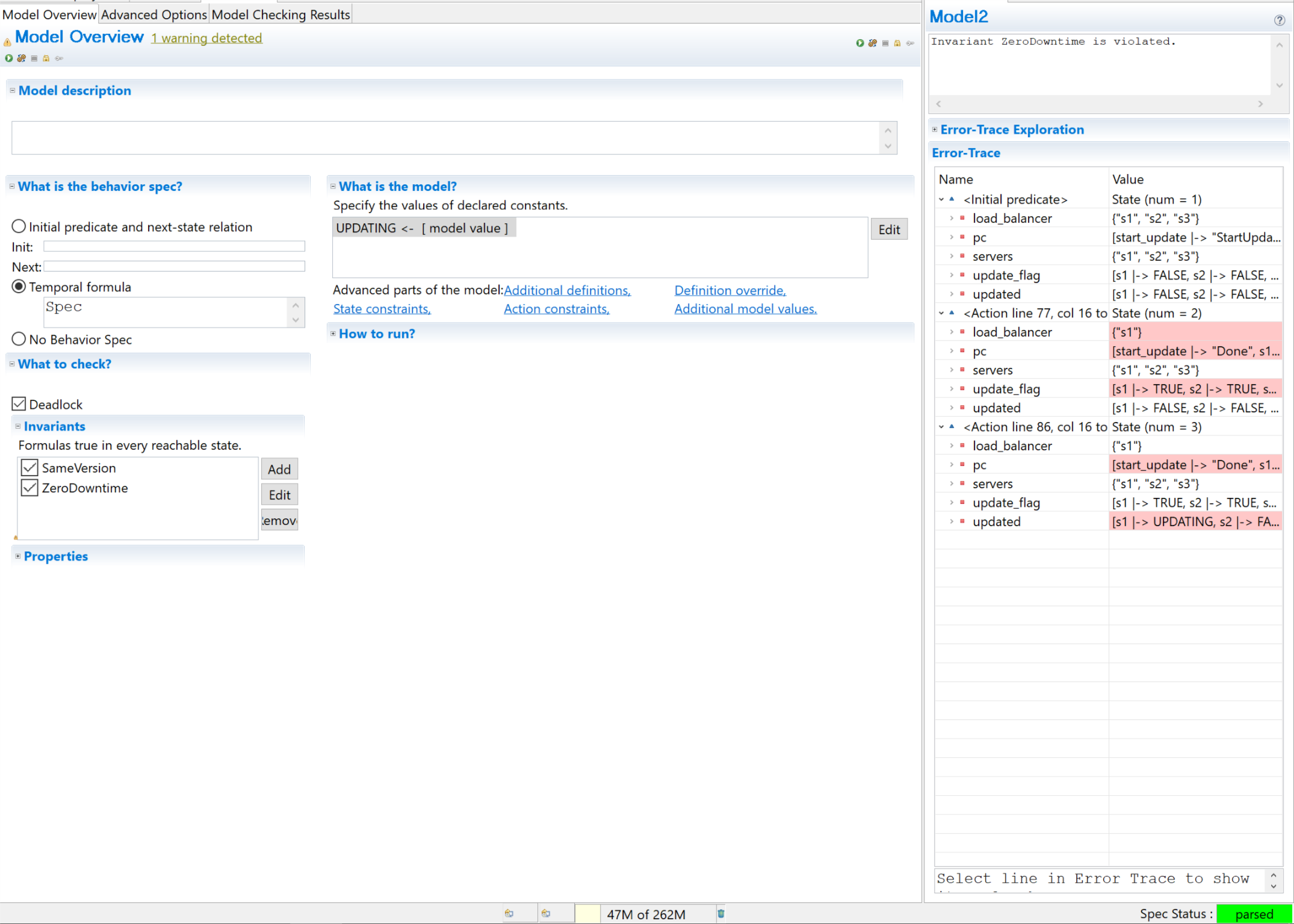
One solution: switch the StartUpdate logic to update only the servers outside the load balancer, and then set the load balancer to point at them instead of s1. We can do this with the set difference operator, which is written as \. Here’s what that looks like:
fair process start_update = "start_update"
begin
StartUpdate:
load_balancer := {"s1"};
+ update_flag := [s \in servers |->
+ IF s = "s1" THEN FALSE ELSE TRUE];
+ Transition:
+ await \A s \in (servers \ load_balancer):
+ updated[s] = TRUE;
+ load_balancer := servers \ load_balancer;
+ update_flag["s1"] := TRUE;
end process;
This works and satisfies both of our safety requirements.
Temporal Logic
“But wait!” you’ve probably said, because you’re a programmer and used to seeing things go horribly wrong. “There’s still one server out of the load balancer!” That is pretty bad, but unfortunately not something we can check in our model.
Just kidding. We can totally check this in our model.
(\A p \in DOMAIN pc: pc[p] = "Done") => load_balancer = servers
=> is implies. A => B means that if A is true, B must also be true. Here we’re saying that when everything’s done running, all the servers have to be in the load balancer.6 Since we’re leaving out the last server, our model fails. We have to explicitly move the last server back into the load balancer:
Transition:
await \A s \in (servers \ load_balancer):
updated[s] = TRUE;
load_balancer := servers \ load_balancer;
update_flag["s1"] := TRUE;
+ Finish:
+ await updated["s1"] = TRUE;
+ load_balancer := load_balancer \union {"s1"};
end process;
Here’s the final spec:
---- MODULE deployments ----
EXTENDS TLC, Integers
CONSTANT UPDATING
(* --algorithm deploy
variables
servers = {"s1", "s2", "s3"},
load_balancer = servers,
update_flag = [s \in servers |-> FALSE],
updated = [s \in servers |-> FALSE];
define
SameVersion ==
\A x, y \in load_balancer:
updated[x] = updated[y]
ZeroDowntime ==
\E server \in load_balancer:
updated[server] /= UPDATING
end define
fair process update_server \in servers
begin
Update:
await update_flag[self];
updated[self] := UPDATING;
FinishUpdate:
updated[self] := TRUE;
end process;
fair process start_update = "start_update"
begin
StartUpdate:
load_balancer := {"s1"};
update_flag := [s \in servers |->
IF s = "s1" THEN FALSE ELSE TRUE];
Transition:
await \A s \in (servers \ load_balancer):
updated[s] = TRUE;
load_balancer := servers \ load_balancer;
update_flag["s1"] := TRUE;
Finish:
await updated["s1"] = TRUE;
load_balancer := load_balancer \union {"s1"};
end process;
end algorithm; *)
====
Extensions
I’ve kept this example simple to minimize the amount of TLA+ syntax we’d need to cover. In reality, deployment can be much messier. However, most circumstances you’d want to model only require just a bit of extra TLA+ knowledge to model. Here are some outlines of that:
- What if the new code has a bug which prevents deployment from working? We can specify a global state that, for any given behavior, is either true or false for all servers:
variables will_update \in {TRUE, FALSE}
- What if the code is fine but individual servers may fail for other reasons? We can make the process branch into multiple timelines with an
eitherstatement:
either
updated[self] := TRUE;
or
updated[self] := CORRUPT;
end either;
We could pass parameters into ZeroDowntime to require a certain number of minimum servers be online, not just one. We could use structures to create multiple types of services that update in different ways with different minimum capacities. We could have two load balancers to simulate a blue-green deployment. We could add an audit log and place constraints on that. We could have lossy communication between servers. TLA+ has the power and flexibility to model all of these cases.
Learn More
If you’re interested in learning more TLA+, I’ve written a beginner-friendly guide that covers everything you need to start writing useful specs. If you’re more interested in the theory behind it, you can download Specifying Systems for free. Feel free to email if you have any questions or issues; as you can tell, I love helping people with this stuff.
- Normally we’d make servers a constant and declare it a set of “model values”, which allows for greater flexibility at model checking time. I’m leaving that out to keep this simpler. [return]
- A gotcha here is that the equals in
updated[x] = updated[y]is an equality check, not an assignment. When initializing variables=is assignment, otherwise it the equality operator. [return] - We actually wrote this spec in PlusCal, a pseudocode-like syntax that translates to the equivalent TLA+ spec. It’s a little less flexible but much easier to read and write. [return]
- Remember to set it as a “model value” and not an “ordinary assignment”, or else TLC will throw an error. [return]
- In reality it’s actually around 10 steps, because most of them lead to redundant states. [return]
- I’m cheating a little here. TLA+ supports writing temporal properties in a more elegant way, but we’d have to make some changes to our spec to support temporal modeling. [return]